Should online communities require people to create accounts before participating?
This question has been a source of disagreement among people who start or manage online communities for decades. Requiring accounts makes some sense since users contributing without accounts are a common source of vandalism, harassment, and low quality content. In theory, creating an account can deter these kinds of attacks while still making it pretty quick and easy for newcomers to join. Also, an account requirement seems unlikely to affect contributors who already have accounts and are typically the source of most valuable contributions. Creating accounts might even help community members build deeper relationships and commitments to the group in ways that lead them to stick around longer and contribute more.
In a new paper published in Communication Research, I worked with Aaron Shaw provide an answer. We analyze data from “natural experiments” that occurred when 136 wikis on Fandom.com started requiring user accounts. Although we find strong evidence that the account requirements deterred low quality contributions, this came at a substantial (and usually hidden) cost: a much larger decrease in high quality contributions. Surprisingly, the cost includes “lost” contributions from community members who had accounts already, but whose activity appears to have been catalyzed by the (often low quality) contributions from those without accounts.
The full citation for the paper is: Hill, Benjamin Mako, and Aaron Shaw. 2020. “The Hidden Costs of Requiring Accounts: Quasi-Experimental Evidence from Peer Production.” Communication Research, 48 (6): 771–95. https://doi.org/10.1177/0093650220910345.
Ever considered doing research about online communities, free culture/software, and peer production full time? It’s PhD admission season and my research group—the Community Data Science Collective—is doing an open-to-anyone Q&A about PhD admissions this Friday November 5th. We’ve got room in the session and its not too late to sign up to join us!
The session will be a good opportunity to hear from and talk to faculty recruiting students to our various programs at the University of Washington, Purdue, and Northwestern and to talk with current and previous students in the group.
The registration deadline for the Q&A session is listed as today but we’ll do what we can to sneak you in even if you register late. That said, please do register ASAP so we can get you the link to the session!
I first started using Debian sometime in the mid 90s and started contributing as a developer and package maintainer more than two decades years ago. My first very first scholarly publication, collaborative work led by Martin Michlmayr that I did when I was still an undergrad at Hampshire College, was about quality and the reliance on individuals in Debian. To this day, many of my closest friends are people I first met through Debian. I met many of them at Debian’s annual conference DebConf.
Given my strong connections to Debian, I find it somewhat surprising that although all of my academic research has focused on peer production, free culture, and free software, I haven’t actually published any Debian related research since that first paper with Martin in 2003!
So it felt like coming full circle when, several days ago, I was able to sit in the virtual DebConf audience and watch two of my graduate student advisees—Kaylea Champion and Wm Salt Hale—present their research about Debian at DebConf21.
Salt presented his masters thesis work which tried to understand the social dynamics behind organizational resilience among free software projects. Kaylea presented her work on a new technique she developed to identifying at risk software packages that are lower quality than we might hope given their popularity (you can read more about Kaylea’s project in our blog post from earlier this year).
And if you’re interested in joining us—perhaps to do more research on FLOSS and/or Debian and/or a graduate degree of your own?—please be in touch with me directly!
The grant will support a bunch of new research to develop and test a theory about the relationship between governance and online community lifecycles. If you’ve been reading this blog for a while, you’ll know that I’ve been involved in a bunch of research to describe how peer production communities tend to follow common patterns of growth and decline as well as a studies that show that many open communities become increasingly closed in ways that deter lots of the kinds contributions that made the communities successful in the first place.
Over the last few years, I’ve worked with Aaron Shaw to develop the outlines of an explanation for why many communities because increasingly closed over time in ways that hurt their ability to integrate contributions from newcomers. Over the course of the work on the CAREER, I’ll be continuing that project with Aaron and I’ll also be working to test that explanation empirically and to develop new strategies about what online communities can do as a result.
In addition to supporting research, the grant will support a bunch of new outreach and community building within the Community Data Science Collective. In particular, I’m planning to use the grant to do a better job of building relationships with community participants, community managers, and others in the platforms we study. I’m also hoping to use the resources to help the CDSC do a better job of sharing our stuff out in ways that are useful as well doing a better job of listening and learning from the communities that our research seeks to inform.
There are many to thank. The proposed work was the direct research of the work I did as the Center for Advanced Studies in the Behavioral Sciences at Stanford where I got to spend the 2018-2019 academic year in Claude Shannon’s old office and talking through these ideas with an incredible range of other scholars over lunch every day. It’s also the product of years of conversations with Aaron Shaw and Yochai Benkler. The proposal itself reflects the excellent work of the whole CDSC who did the work that made the award possible and provided me with detailed feedback on the proposal itself.
I wrote this blog post with Kaylea Champion and a version of this post was originally posted on the Community Data Science Collective blog.
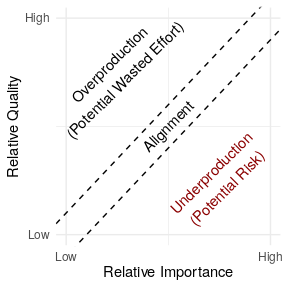
Critical software we all rely on can silently crumble away beneath us. Unfortunately, we often don’t find out software infrastructure is in poor condition until it is too late. Over the last year or so, I have been supporting Kaylea Champion on a project my group announced earlier to measure software underproduction—a term we use to describe software that is low in quality but high in importance.
Underproduction reflects an important type of risk in widely used free/libre open source software (FLOSS) because participants often choose their own projects and tasks. Because FLOSS contributors work as volunteers and choose what they work on, important projects aren’t always the ones to which FLOSS developers devote the most attention. Even when developers want to work on important projects, relative neglect among important projects is often difficult for FLOSS contributors to see.
Conceptual diagram showing how our conception of underproduction relates to quality and importance of software.
In the paper, we describe a general approach for detecting “underproduced” software infrastructure that consists of five steps: (1) identifying a body of digital infrastructure (like a code repository); (2) identifying a measure of quality (like the time to takes to fix bugs); (3) identifying a measure of importance (like install base); (4) specifying a hypothesized relationship linking quality and importance if quality and importance are in perfect alignment; and (5) quantifying deviation from this theoretical baseline to find relative underproduction.
To show how our method works in practice, we applied the technique to an important collection of FLOSS infrastructure: 21,902 packages in the Debian GNU/Linux distribution. Although there are many ways to measure quality, we used a measure of how quickly Debian maintainers have historically dealt with 461,656 bugs that have been filed over the last three decades. To measure importance, we used data from Debian’s Popularity Contest opt-in survey. After some statistical machinations that are documented in our paper, the result was an estimate of relative underproduction for the 21,902 packages in Debian we looked at.
One of our key findings is that underproduction is very common in Debian. By our estimates, at least 4,327 packages in Debian are underproduced. As you can see in the list of the “most underproduced” packages—again, as estimated using just one more measure—many of the most at risk packages are associated with the desktop and windowing environments where there are many users but also many extremely tricky integration-related bugs.
These 30 packages have the highest level of underproduction in Debian according to our analysis.
We hope these results are useful to folks at Debian and the Debian QA team. We also hope that the basic method we’ve laid out is something that others will build off in other contexts and apply to other software repositories.
Paper Citation: Kaylea Champion and Benjamin Mako Hill. 2021. “Underproduction: An Approach for Measuring Risk in Open Source Software.” In Proceedings of the IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER 2021). IEEE.
Contact Kaylea Champion (kaylea@uw.edu) with any questions or if you are interested in following up.
In May 2019, my research group was invited to give short remarks on the impact of Janet Fulk and Peter Monge at the International Communication Association‘s annual meeting as part of a session called “Igniting a TON (Technology, Organizing, and Networks) of Insights: Recognizing the Contributions of Janet Fulk and Peter Monge in Shaping the Future of Communication Research.”
Youtube: Mako Hill @ Janet Fulk and Peter Monge Celebration at ICA 2019
I gave a five-minute talk on Janet and Peter’s impact to the work of the Community Data Science Collective by unpacking some of the cryptic acronyms on the CDSC-UW lab’s whiteboard as well as explaining that our group has a home in the academic field of communication, in no small part, because of the pioneering scholarship of Janet and Peter. You can view the talk in WebM or on Youtube.
Introducing new technology into a work place is often disruptive, but what if your work was also completely mediated by technology? This is exactly the case for the teams of volunteer moderatorswho work to regulate content and protect online communities from harm. What happens when the social media platforms these communities rely on change completely? How do moderation teams overcome the challenges caused by new technological environments? How do they do so while managing a “brand new” community with tens of thousands of users?
For a new study that will be published in CSCW in November, we interviewed 14 moderators of 8 “subreddit” communities from the social media aggregation and discussion platform Reddit to answer these questions. We chose these communities because each community had recently adopted the real-time chat platform Discord to support real-time chat in their community. This expansion into Discord introduced a range of challenges—especially for the moderation teams of large communities.
We found that moderation teams of large communities improvised their own creative solutions to challenges they faced by building bots on top of Discord’s API. This was not too shocking given that APIs and bots are frequently cited as tools that allow innovation and experimentation when scaling up digital work. What did surprise us, however, was how important moderators’ past experiences were in guiding the way they used bots. In the largest communities that faced the biggest challenges, moderators relied on bots to reproduce the tools they had used on Reddit. The moderators would often go so far as to give their bots the names of moderator tools available on Reddit. Our findings suggest that support for user-driven innovation is important not only in that it allows users to explore new technological possibilities but also in that it allows users to mine their past experiences to introduce old systems into new environments.
What Challenges Emerged in Discord?
Discord’s text channels allow for more natural, in the moment conversations compared to Reddit. In Discord, this social aspect also made moderation work much more difficult. One moderator explained:
“It’s kind of rough because if you miss it, it’s really hard to go back to something that happened eight hours ago and the conversation moved on and be like ‘hey, don’t do that.’ ”
Moderators we spoke to found that the work of managing their communities was made even more difficult by their community’s size:
On the day to day of running 65,000 people, it’s literally like running a small city…We have people that are actively online and chatting that are larger than a city…So it’s like, that’s a lot to actually keep track of and run and manage.”
The moderators of large communities repeatedly told us that the tools provided to moderators on Discord were insufficient. For example, they pointed out tools like Discord’s Audit Log was inadequate for keeping track of the tens of thousands of members of their communities. Discord also lacks automated moderation tools like the Reddit’s Automoderator and Modmail leaving moderators on Discord with few tools to scale their work and manage communications with community members.
How Did Moderation Teams Overcome These Challenges?
The moderation teams we talked with adapted to these challenges through innovative uses of Discord’s API toolkit. Like many social media platforms, Discord offers a public API where users can develop apps that interact with the platform through a Discord “bot.” We found that these bots play a critical role in helping moderation teams manage Discord communities with large populations.
Guided by their experience with using tools like Automoderator on Reddit, moderators working on Discord built bots with similar functionality to solve the problems associated with scaled content and Discord’s fast-paced chat affordances. This bots would search for regular expressions and URLs that go against the community’s rules:
“It makes it so that rather than having to watch every single channel all of the time for this sort of thing or rely on users to tell us when someone is basically running amuck, posting derogatory terms and terrible things that Discord wouldn’t catch itself…so it makes it that we don’t have to watch every channel.”
Bots were also used to replace Discord’s Audit Log feature with what moderators referred to often as “Mod logs”—another term borrowed from Reddit. Moderators will send commands to a bot like “!warn username” to store information such as when a member of their community has been warned for breaking a rule and automatically store this information in a private text channel in Discord. This information helps organize information about community members, and it can be instantly recalled with another command to the bot to help inform future moderation actions against other community members.
Finally, moderators also used Discord’s API to develop bots that functioned virtually identically to Reddit’s Modmail tool. Moderators are limited in their availability to answer questions from members of their community, but tools like the “Modmail” helps moderation teams manage this problem by mediating communication to community members with a bot:
“So instead of having somebody DM a moderator specifically and then having to talk…indirectly with the team, a [text] channel is made for that specific question and everybody can see that and comment on that. And then whoever’s online responds to the community member through the bot, but everybody else is able to see what is being responded.”
The tools created with Discord’s API — customizable automated content moderation, Mod logs, and a Modmail system — all resembled moderation tools on Reddit. They even bear their names! Over and over, we found that moderation teams essentially created and used bots to transform aspects of Discord, like text channels into Mod logs and Mod Mail, to resemble the same tools they were using to moderate their communities on Reddit.
What Does This Mean for Online Communities?
We think that the experience of moderators we interviewed points to a potentially important underlooked source of value for groups navigating technological change: the potent combination of users’ past experience combined with their ability to redesign and reconfigure their technological environments. Our work suggests the value of innovation platforms like APIs and bots is not only that they allow the discovery of “new” things. Our work suggests that these systems value also flows from the fact that they allow the re-creation of the the things that communities already know can solve their problems and that they already know how to use.
Informal online learning communities are one of the most exciting and successful ways to engage young people in technology. As the most successful example of the approach, over 40 million children from around the world have created accounts on the Scratch online community where they learn to code by creating interactive art, games, and stories. However, despite its enormous reach and its focus on inclusiveness, participation in Scratch is not as broad as one would hope. For example, reflecting a trend in the broader computing community, more boys have signed up on the Scratch website than girls.
In a recently published paper, I worked with several colleagues from the Community Data Science Collective to unpack the dynamics of unequal participation by gender in Scratch by looking at whether Scratch users choose to share the projects they create. Our analysis took advantage of the fact that less than a third of projects created in Scratch are ever shared publicly. By never sharing, creators never open themselves to the benefits associated with interaction, feedback, socialization, and learning—all things that research has shown participation in Scratch can support.
Overall, we found that boys on Scratch share their projects at a slightly higher rate than girls. Digging deeper, we found that this overall average hid an important dynamic that emerged over time. The graph below shows the proportion of Scratch projects shared for male and female Scratch users’ 1st created projects, 2nd created projects, 3rd created projects, and so on. It reflects the fact that although girls share less often initially, this trend flips over time. Experienced girls share much more than often than boys!
Proportion of projects shared by gender across experience levels, measured as the number of projects created, for 1.1 million Scratch users. Projects created by girls are less likely to be shared than those by boys until about the 9th project is created. The relationship is subsequently reversed.
We unpacked this dynamic using a series of statistical models estimated using data from over 5 million projects by over a million Scratch users. This set of analyses echoed our earlier preliminary finding—while girls were less likely to share initially, more experienced girls shared projects at consistently higher rates than boys. We further found that initial differences in sharing between boys and girls could be explained by controlling for differences in project complexity and in the social connectedness of the project creator.
Another surprising finding is that users who had received more positive peer feedback, at least as measured by receipt of “love its” (similar to “likes” on Facebook), were less likely to share their subsequent projects than users who had received less. This relation was especially strong for boys and for more experienced Scratch users. We speculate that this could be due to a phenomenon known in the music industry as “sophomore album syndrome” or “second album syndrome”—a term used to describe a musician who has had a successful first album but struggles to produce a second because of increased pressure and expectations caused by their previous success
Online anonymity often gets a bad rap and complaints about antisocial behavior from anonymous Internet users are as old as the Internet itself. On the other hand, research has shown that many Internet users seek out anonymity to protect their privacy while contributing things of value. Should people seeking to contribute to open collaboration projects like open source software and citizen science projects be required to give up identifying information in order to participate?
I was part of a team led by Nora McDonald that conducted a two-part study to better understand how open collaboration projects balance the threats of bad behavior with the goal of respecting contributors’ expectations of privacy. First, we interviewed eleven people from five different open collaboration “service providers” to understand what threats they perceive to their projects’ mission and how these threats shape privacy and security decisions when it comes to anonymous contributions. Second, we analyzed discussions about anonymous contributors on publicly available logs of the English language Wikipedia mailing list from 2010 to 2017.
In the interview study, we identified three themes that pervaded discussions of perceived threats. These included threats to:
community norms, such as harrassment;
sustaining participation, such as loss of or failure to attract volunteers; and
contribution quality, low-quality contributions drain community resources.
We found that open collaboration providers were most concerned with lowering barriers to participation to attract new contributors. This makes sense given that newbies are the lifeblood of open collaboration communities. We also found that service providers thought of allowing anonymous contributions as a way of offering low barriers to participation, not as a way of helping contributors manage their privacy. They imagined that anonymous contributors who wanted to remain in the community would eventually become full participants by registering for an account and creating an identity on the site. This assumption was evident in policies and technical features of collaboration platforms that barred anonymous contributors from participating in discussions, receiving customized suggestions, or from contributing at all in some circumstances. In our second study of the English language Wikipedia public email listserv, we discovered that the perspectives we encountered in interviews also dominated discussions of anonymity on Wikipedia. In both studies, we found that anonymous contributors were seen as “second-class citizens.
This is not the way anonymous contributors see themselves. In a study we published two years ago, we interviewed people who sought out privacy when contributing to open collaboration projects. Our subjects expressed fears like being doxed, shot at, losing their job, or harassed. Some were worried about doing or viewing things online that violated censorship laws in their home country. The difference between the way that anonymity seekers see themselves and the way they are seen by service providers was striking.
One cause of this divergence in perceptions around anonymous contributors uncovered by our new paper is that people who seek out anonymity are not able to participate fully in the process of discussing and articulating norms and policies around anonymous contribution. People whose anonymity needs means they cannot participate in general cannot participate in the discussions that determine who can participate.
We conclude our paper with the observation that, although social norms have played an important role in HCI research, relying on them as a yardstick for measuring privacy expectations may leave out important minority experiences whose privacy concerns keep them from participating in the first place. In online communities like open collaboration projects, social norms may best reflect the most privileged and central users of a system while ignoring the most vulnerable
The award itself is a plush fish with a parasitic lamprey attached to it.
As of yesterday, I’m officially a research symbiont! A committee of health scientists saw fit to give me a Research Symbiont Award which is awarded annually to “a scientist working in any field who has shared data beyond the expectations of their field.” The award was announced at Pacific Symposium on Biocomputing and came with a trip to Hawaii (which I couldn’t take!) and the awesome plush fish with a parasitic lamprey shown in the picture.
Sharing data in ways that are useful to others is a ton of work. It takes more time than you might imagine to prepare, polish, validate, test, and document data for others to use. I think I spent more time working with Andrés Monroy-Hernández on the Scratch Research Dataset than I have any single empirical paper! Although I spent the time doing it because I think it’s an important way to contribute to science, recognition in the form of an award—and a cute stuffed parasitic fish—is super appreciated as well!
Leaders and scholars of online communities tend of think of community growth as the aggregate effect of inexperienced individuals arriving one-by-one. However, there is increasing evidence that growth in many online communities today involves newcomers arriving in groups with previous experience together in other communities. This difference has deep implications for how we think about the process of integrating newcomers. Instead of focusing only on individual socialization into the group culture, we must also understand how to manage mergers of existing groups with distinct cultures. Unfortunately, online community mergers have, to our knowledge, never been studied systematically.
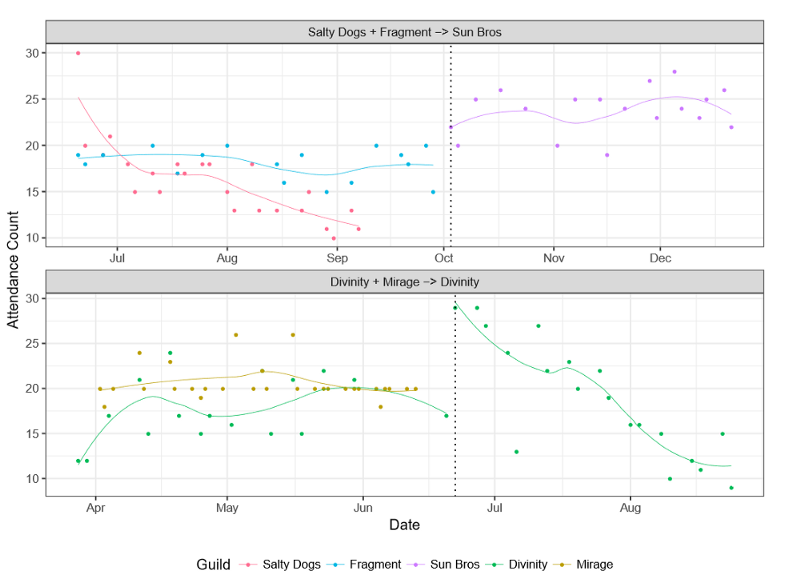
To better understand mergers, my student Charlie Kiene spent six months in 2017 conducting ethnographic participant observation in two World of Warcraft raid guilds planning and undergoing mergers. The results—visible in the attendance plot below—shows that the top merger led to a thriving and sustainable community while the bottom merger led to failure and the eventual dissolution of the group. Why did one merger succeed while the other failed? What can managers of other communities learn from these examples?
In a new paper that will be published in the Proceedings of of the ACM Conference on Computer-supported Cooperative Work and Social Computing (CSCW) and that Charlie will present in New Jersey next month, I teamed up with Charlie and Aaron Shaw try to answer these questions.
Raid team attendance before and after merging. Guilds were given pseudonyms to protect the identity of the research subjects.
In our research setting, World of Warcraft (WoW), players form organized groups called “guilds” to take on the game’s toughest bosses in virtual dungeons that are called “raids.” Raids can be extremely challenging, and they require a large number of players to be successful. Below is a video demonstrating the kind of communication and coordination needed to be successful as a raid team in WoW.
Because participation in a raid guild requires time, discipline, and emotional investment, raid guilds are constantly losing members and recruiting new ones to resupply their ranks. One common strategy for doing so is arranging formal mergers. Our study involved following two such groups as they completed mergers. To collect data for our study, Charlie joined both groups, attended and recorded all activities, took copious field notes, and spent hours interviewing leaders.
Although our team did not anticipate the divergent outcomes shown in the figure above when we began, we analyzed our data with an eye toward identifying themes that might point to reasons for the success of one merger and the failure of the other. The answers that emerged from our analysis suggest that the key differences that led one merger to be successful and the other to fail revolved around differences in the ways that the two mergers managed organizational culture. This basic insight is supported by a body of research about organizational culture in firms but seem to have not made it onto the radar of most members or scholars of online communities. My coauthors and I think more attention to the role that organizational culture plays in online communities is essential.
We found evidence of cultural incompatibility in both mergers and it seems likely that some degree of cultural clashes is inevitable in any merger. The most important result of our analysis are three observations we drew about specific things that the successful merger did to effectively manage organizational culture. Drawn from our analysis, these themes point to concrete things that other communities facing mergers—either formal or informal—can do.
A recent, random example of a guild merger recruitment post found on the WoW forums.
First, when planning mergers, groups can strategically select other groups with similar organizational culture. The successful merger in our study involved a carefully planned process of advertising for a potential merger on forums, testing out group compatibility by participating in “trial” raid activities with potential guilds, and selecting the guild that most closely matched their own group’s culture. In our settings, this process helped prevent conflict from emerging and ensured that there was enough common ground to resolve it when it did.
Second, leaders can plan intentional opportunities to socialize members of the merged or acquired group. The leaders of the successful merger held community-wide social events in the game to help new members learn their community’s norms. They spelled out these norms in a visible list of rules. They even included the new members in both the brainstorming and voting process of changing the guild’s name to reflect that they were a single, new, cohesive unit. The leaders of the failed merger lacked any explicitly stated community rules, and opportunities for socializing the members of the new group were virtually absent. Newcomers from the merged group would only learn community norms when they broke one of the unstated social codes.
The guild leaders in the successful merger documented every successful high end raid boss achievement in a community-wide “Hall of Fame” journal. A screenshot is taken with every guild member who contributed to the achievement and uploaded to a “Hall of Fame” page.
Third and finally, our study suggested that social activities can be used to cultivate solidarity between the two merged groups, leading to increased retention of new members. We found that the successful guild merger organized an additional night of activity that was socially-oriented. In doing so, they provided a setting where solidarity between new and existing members can cultivate and motivate their members to stick around and keep playing with each other—even when it gets frustrating.
Our results suggest that by preparing in advance, ensuring some degree of cultural compatibility, and providing opportunities to socialize newcomers and cultivate solidarity, the potential for conflict resulting from mergers can be mitigated. While mergers between firms often occur to make more money or consolidate resources, the experience of the failed merger in our study shows that mergers between online communities put their entire communities at stake. We hope our work can be used by leaders in online communities to successfully manage potential conflict resulting from merging or acquiring members of other groups in a wide range of settings.
Much more detail is available our paper which will be published open access and which is currently available as a preprint.
Couchsurfing and Airbnb are websites that connect people with an extra guest room or couch with random strangers on the Internet who are looking for a place to stay. Although Couchsurfing predates Airbnb by about five years, the two sites are designed to help people do the same basic thing and they work in extremely similar ways. They differ, however, in one crucial respect. On Couchsurfing, the exchange of money in return for hosting is explicitly banned. In other words, couchsurfing only supports the social exchange of hospitality. On Airbnb, users must use money: the website is a market on which people can buy and sell hospitality.
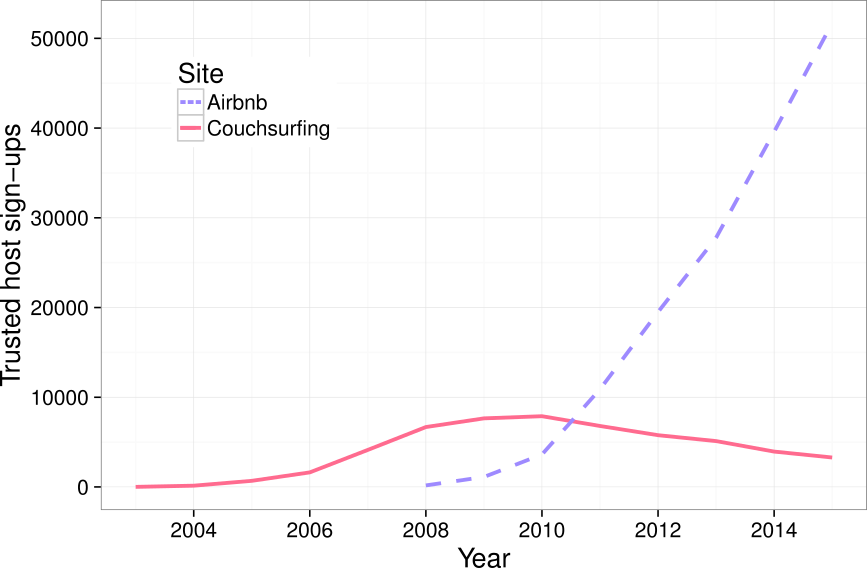
Comparison of yearly sign-ups of trusted hosts on Couchsurfing and Airbnb. Hosts are “trusted” when they have any form of references or verification in Couchsurfing and at least one review in Airbnb.
The figure above compares the number of people with at least some trust or verification on both Couchsurfing and Airbnb based on when each user signed up. The picture, as I have argued elsewhere, reflects a broader pattern that has occurred on the web over the last 15 years. Increasingly, social-based systems of production and exchange, many like Couchsurfing created during the first decade of the Internet boom, are being supplanted and eclipsed by similar market-based players like Airbnb.
In a paper led by Max Klein that was recently published and will be presented at the ACM Conference on Computer-supported Cooperative Work and Social Computing (CSCW) which will be held in Jersey City in early November 2018, we sought to provide a window into what this change means and what might be at stake. At the core of our research were a set of interviews we conducted with “dual-users” (i.e. users experienced on both Couchsurfing and Airbnb). Analyses of these interviews pointed to three major differences, which we explored quantitatively from public data on the two sites.
First, we found that users felt that hosting on Airbnb appears to require higher quality services than Couchsurfing. For example, we found that people who at some point only hosted on Couchsurfing often said that they did not host on Airbnb because they felt that their homes weren’t of sufficient quality. One participant explained that:
“I always wanted to host on Airbnb but I didn’t actually have a bedroom that I felt would be sufficient for guests who are paying for it.”
An another interviewee said:
“If I were to be paying for it, I’d expect a nice stay. This is why I never Airbnb-hosted before, because recently I couldn’t enable that [kind of hosting].”
We conducted a quantitative analysis of rates of Airbnb and Couchsurfing in different cities in the United States and found that median home prices are positively related to number of per capita Airbnb hosts and a negatively related to the number of Couchsurfing hosts. Our exploratory models predicted that for each $100,000 increase in median house price in a city, there will be about 43.4 more Airbnb hosts per 100,000 citizens, and 3.8 fewer hosts on Couchsurfing.
A second major theme we identified was that, while Couchsurfing emphasizes people, Airbnb places more emphasis on places. One of our participants explained:
“People who go on Airbnb, they are looking for a specific goal, a specific service, expecting the place is going to be clean […] the water isn’t leaking from the sink. I know people who do Couchsurfing even though they could definitely afford to use Airbnb every time they travel, because they want that human experience.”
In a follow-up quantitative analysis we conducted of the profile text from hosts on the two websites with a commonly-used system for text analysis called LIWC, we found that, compared to Couchsurfing, a lower proportion of words in Airbnb profiles were classified as being about people while a larger proportion of words were classified as being about places.
Finally, our research suggested that although hosts are the powerful parties in exchange on Couchsurfing, social power shifts from hosts to guests on Airbnb. Reflecting a much broader theme in our interviews, one of our participants expressed this concisely, saying:
“On Airbnb the host is trying to attract the guest, whereas on Couchsurfing, it works the other way round. It’s the guest that has to make an effort for the host to accept them.”
Previous research on Airbnb has shown that guests tend to give their hosts lower ratings than vice versa. Sociologists have suggested that this asymmetry in ratings will tend to reflect the direction of underlying social power balances.
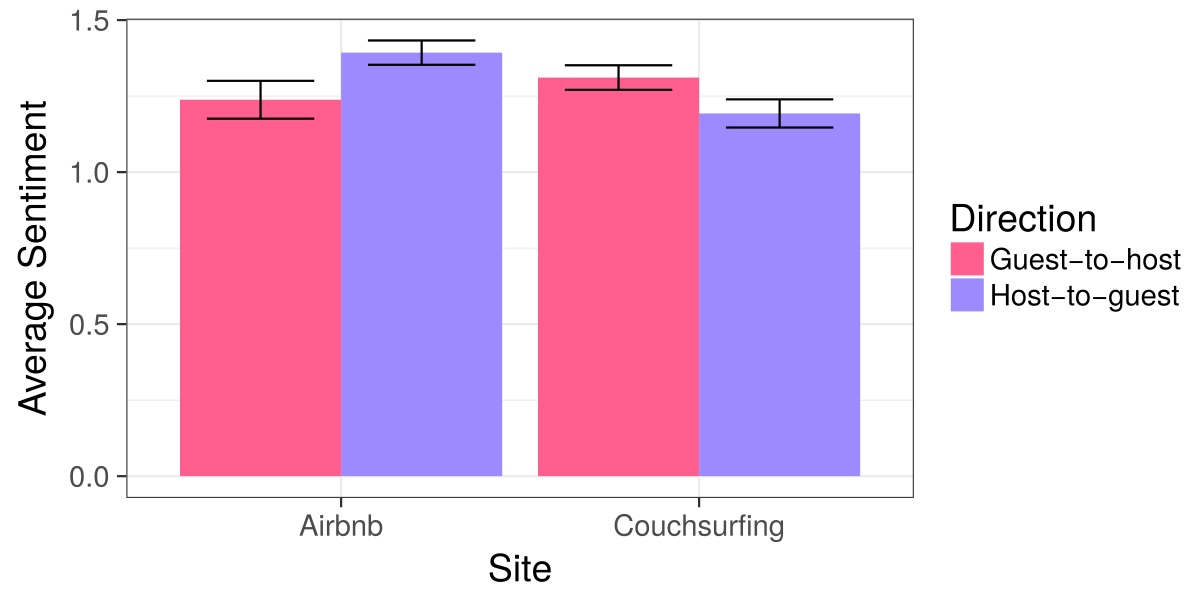
Average sentiment score of reviews in Airbnb and Couchsurfing, separated by direction (guest-to-host, or host-to-guest). Error bars show the 95% confidence interval.
We both replicated this finding from previous work and found that, as suggested in our interviews, the relationship is reversed on Couchsurfing. As shown in the figure above, we found Airbnb guests will typically give a less positive review to their host than vice-versa while in Couchsurfing guests will typically a more positive review to the host.
As Internet-based hospitality shifts from social systems to the market, we hope that our paper can point to some of what is changing and some of what is lost. For example, our first result suggests that less wealthy participants may be cut out by market-based platforms. Our second theme suggests a shift toward less human-focused modes of interaction brought on by increased “marketization.” We see the third theme as providing somewhat of a silver-lining in that shifting power toward guests was seen by some of our participants as a positive change in terms of safety and trust in that guests. Travelers in unfamiliar places often are often vulnerable and shifting power toward guests can be helpful.
Although our study is only of Couchsurfing and Airbnb, we believe that the shift away from social exchange and toward markets has broad implications across the sharing economy. We end our paper by speculating a little about the generalizability of our results. I have recently spoken at much more length about the underlying dynamics driving the shift we describe in my recent LibrePlanet keynote address.
More details are available in our paper which we have made available as a preprint on our website. The final version is behind a paywall in the ACM digital library.
Every CASBS study is labeled with a list of “ghosts” who previously occupied the study. This year, I’m spending the year in Study 50 where I’m haunted by an incredible cast that includes many people whose scholarship has influenced and inspired me.
The top part of the list of ghosts in Study #50 at CASBS.
Foremost among this group is Study 50’s third occupant: Claude Shannon.¹
At 21 years old, Shannon’s masters thesis (sometimes cited as the most important masters thesis in history) proved that electrical circuits could encode any relationship expressible in Boolean logic and opened the door to digital computing. Incredibly, this is almost never cited as Shannon’s most important contribution. That came in 1948 when he published a paper titled A Mathematical Theory of Communication which effectively created the field of information theory. Less than a decade after its publication, Aleksandr Khinchin (the mathematician behind my favorite mathematical constant) described the paper saying:
Rarely does it happen in mathematics that a new discipline achieves the character of a mature and developed scientific theory in the first investigation devoted to it…So it was with information theory after the work of Shannon.
As someone whose own research is seeking to advance computation and mathematical study of communication, I find it incredibly propitious to be sharing a study with Shannon.
Although I teach in a communication department, I know Shannon from my background in computing. I’ve always found it curious that, despite the fact Shannon’s 1948 paper is almost certainly the most important single thing ever published with the word “communication” in its title, Shannon is rarely taught in communication curricula is sometimes completely unknown to communication scholars.
In this regard, I’ve thought a lot about this passage in Robert’s Craig’s influential article “Communication Theory as a Field” which argued:
In establishing itself under the banner of communication, the discipline staked an academic claim to the entire field of communication theory and research—a very big claim indeed, since communication had already been widely studied and theorized. Peters writes that communication research became “an intellectual Taiwan-claiming to be all of China when, in fact, it was isolated on a small island” (p. 545). Perhaps the most egregious case involved Shannon’s mathematical theory of information (Shannon & Weaver, 1948), which communication scholars touted as evidence of their field’s potential scientific status even though they had nothing whatever to do with creating it, often poorly understood it, and seldom found any real use for it in their research.
In preparation for moving into Study 50, I read a new biography of Shannon by Jimmy Soni and Rob Goodman and was excited to find that Craig—although accurately describing many communication scholars’ lack of familiarity—almost certainly understated the importance of Shannon to communication scholarship.
For example, the book form of Shannon’s 1948 article was published by University Illinois on the urging of and editorial supervision of Wilbur Schramm (one of the founders of modern mass communication scholarship) who was a major proponent of Shannon’s work. Everett Rogers (another giant in communication) devotes a chapter of his “History of Communication Studies”² to Shannon and to tracing his impact in communication. Both Schramm and Rogers built on Shannon in parts of their own work. Shannon has had an enormous impact, it turns out, in several subareas of communication research (e.g., attempts to model communication processes).
Although I find these connections exciting. My own research—like most of the rest of communication—is far from the substance of technical communication processes at the center of Shannon’s own work. In this sense, it can be a challenge to explain to my colleagues in communication—and to my fellow CASBS fellows—why I’m so excited to be sharing a space with Shannon this year.
Upon reflection, I think it boils down to two reasons:
Shannon’s work is both mathematically beautiful and incredibly useful. His seminal 1948 article points to concrete ways that his theory can be useful in communication engineering including in compression, error correcting codes, and cryptography. Shannon’s focus on research that pushes forward the most basic type of basic research while remaining dedicated to developing solutions to real problems is a rare trait that I want to feature in my own scholarship.
Shannon was incredibly playful. Shannon played games, juggled constantly, and was always seeking to teach others to do so. He tinkered, rode unicycles, built a flame-throwing trumpet, and so on. With Marvin Minsky, he invented the “ultimate machine”—a machine that’s only function is to turn itself off—which he kept on his desk.
A version of the Shannon’s “ultimate machine” that is sitting on my desk at CASBS.
I have no misapprehension that I will accomplish anything like Shannon’s greatest intellectual achievements during my year at CASBS. I do hope to be inspired by Shannon’s creativity, focus on impact, and playfulness. In my own little ways, I hope to build something at CASBS that will advance mathematical and computational theory in communication in ways that Shannon might have appreciated.
Incredibly, the year that Shannon was in Study 50, his neighbor in Study 51 was Milton Friedman. Two thoughts: (i) Can you imagine?! (ii) I definitely chose the right study!
Rogers book was written, I found out, during his own stint at CASBS. Alas, it was not written in Study 50.
On September 4th, I’ll be starting a fellowship at the Center for Advanced Studies in the Behavioral Sciences (CASBS), a wonderful social science research institute at Stanford that’s perched on a hill overlooking Palo Alto and the San Francisco Bay. The fellowship is a one-year gig and I’ll be back in Seattle next June.
The only real downside of the fellowship is that it means that I’ll be spending the academic year away from Seattle. I’m going to miss working out of UW, my department, and the Community Data Science Collective lab here enormously.
In a personal sense, it means I’ll be leaving a wonderful community in Seattle in and around my home at Extraordinary Least Squares. I’m going to miss folks deeply and I look forward to returning.
Of course, I’m also pretty excited about moving to Palo Alto. It will be the first time either Mika or I have lived in California and we hope to take advantage of the opportunity.
Please help us do so! If you’re at Stanford, in Silicon Valley, or are anywhere in the Bay Area and want to meet up, please don’t hesitate to get in contact! We’ll be arriving with very little community and I’m really interested in meeting and making friends and taking advantage of my nine-months in the area to make connections!