A month ago, Mark Donfried from the Institute for Cultural Diplomacy (ICD) — an organization dedicated to promoting open dialogue — sent me this letter threatening me with legal action because of contributions I’ve made to Wikipedia. Yesterday, he sent me this followup threat.
According to the letters, Donfried has threatened me with legal action because I participated in a discussion on Wikipedia that resulted in his organization’s article being deleted. It is not anything I wrote in any Wikipedia article that made Donfried so upset — although Donfried is also unhappy about at least one off-hand comment I made during the deletion discussion on a now-deleted Wikipedia process page. Donfried is unhappy that my actions, in small part, have resulted in his organization not having an article in Wikipedia. He is able to threaten me personally because — unlike many people — I edit Wikipedia using my real, full, name.
Donfried’s letter is the latest step in a saga that has been ongoing since last June. It has been a frustrating learning experience for me that has made me worried about Wikipedia, its processes, and its future.
In Wikipedia, debates can be won by stamina. If you care more and argue longer, you will tend to get your way. The result, very often, is that individuals and organizations with a very strong interest in having Wikipedia say a particular thing tend to win out over other editors who just want the encyclopedia to be solid, neutral, and reliable. These less-committed editors simply have less at stake and their attention is more distributed.
The ICD is a non-profit organization based in Berlin. According to its own website, a large part of the organization’s activities are based around arranging conferences. Its goals — peace, cultural interchange, human rights — are admirable and close to my heart. Its advisors and affiliates are impressive.
I had never heard of the ICD before their founder, Mark Donfried, emailed me in April 2012 asking me to give a keynote address at their conference on “The 2012 International Symposium on Cultural Diplomacy & Human Rights.” I replied, interested, but puzzled because my own research seems very far afield of both “cultural diplomacy” (which I had never heard of) and human rights. I replied saying:
What would you like me to talk about — I ask because I don’t consider myself an expert in (or even particularly knowledgeable about) cultural diplomacy. Did someone else refer you to me?
Donfried replied with a long message — seemingly copy and pasted — thanking me for considering attending and asking me for details of my talk. I replied again repeating text from my previous email and asking why he was interested in me. Donfried suggested a phone call to talk about details. But by this point, I had looked around the web for information about the ICD and had decided to decline the invitation.
Among things I found was a blog post by my friend James Grimmelmann that suggests that, at least in his case, the ICD had a history of sending unsolicited email and an apparently inability to take folks off their email lists even after repeated requests.
I also read the Wikipedia article about the ICD. Although the Wikipedia article was long and detailed, it sent off some internal Wikipedian-alarm-bells for me. The page read, to me, like an advertisement or something written by the organization being described; it simply did not read — to me — like an encyclopedia article written by a neutral third-party.
I looked through the history of the article and found that the article had been created by a user called Icd_berlin who had made no other substantive edits to the encyclopedia. Upon further examination, I found that almost all other significant content contributions were from a series of anonymous editors with IP addresses associated with Berlin. I also found that a couple edits had removed criticism when it had been added to the article. The criticism was removed by an anonymous editor from Berlin.
Criticisms on the article included links to a website called “Inside the ICD” which was a website that mostly consisted of comments by anonymous people claiming to be former interns of the ICD complaining about the working conditions at the organization. There were also many very positive descriptions of work at the ICD. A wide array of pseudonymous users on the site accused the negative commenters of being liars and detractors and the positive commenters of being ICD insiders.
I also found that there had been evidence on Wikipedia — also removed without discussion by an anonymous IP from Berlin — of an effort launched by the youth wing of ver.di — one of the largest trade unions in Germany to “campaign for good internships at the ICD.” Although details of the original campaign have been removed from ver.di’s website, the campaigned ended after coming to an agreement with the ICD that made explicit a set of expectations and created an Intern Council.
Although the article about ICD on Wikipedia had many citations, many were to the ICD’s own website. Most of the rest were to articles that only tangentially mentioned the ICD. Many were about people with ICD connections but did not mention the ICD at all.
As Wikipedia editor, I was worried that Wikipedia’s policies on conflict of interest, advertising, neutrality, and notability were not being served by the article in its state. But as someone with no real experience or knowledge of the ICD, I wasn’t sure what to do. I posted a request for help on Wikipedia asking for others to get involved and offer their opinions.
It turns out, there were several editors who had tried to improve the article in the past and had been met by pro-ICD editors reverting their changes. Eventually, those editors lost patience or simply moved on to other topics.
By raising the issue again, I kicked off a round of discussion about the article. At the termination of that discussion, the article was proposed for deletion under Wikipedia’s Articles for Deletion policy. A new Wikipedia editor began working enthusiastically to keep the article by adding links and by arguing that the article should stay. The new user edited the Wikipedia article about me to accuse me of slander and defamation although they removed that claim after I tried to explain that I was only trying to help. I spent quite a bit of time trying to rewrite and improve the article during the deletion discussion and I went — link by link — through the many dozens of citations.
During the deletion discussion, Mark Donfried contacted me over email and explained that his representatives had told him that I was working against the ICD in Wikipedia. He suggested that we meet. We had a tentative plan to meet in Berlin on an afternoon last July but, in the end, I was too busy trying to submit my thesis proposal and neither of us followed up to confirm a particular time within the time window we had set. I have still never met him.
My feeling, toward the end of the deletion discussion on Wikipedia, was mostly exasperation. Somewhat reluctantly, I voted to delete the article saying:
Delete – This AFD is a complete mess for all the reasons that the article itself is. Basically: there are a small number of people who seem to have a very strong interest in the Institute for Cultural Diplomacy having an article in Wikipedia and, from what I can tell, very little else. Hessin fahem, like all the major contributors to the page, joined Wikipedia in order to participate in this issue.
This article has serious problems. I have posted a detailed list of my problems on the article talk page: primary sources, conflict of interest for nearly all substantive contributions and reading like an advert are the biggest issues. My efforts to list these problems were reverted without discussion by an anonymous editor from Berlin.
I have seen no evidence that the Institute for Cultural Diplomacy satisfies WP:ORG but I agree that it is possible that it does. I strongly agree with Arxiloxos that articles should always be fixed, and not deleted, if they are fixable. But I also know that Wikipedia does not deserve this article, that I don’t know to fix it, and that despite my efforts to address these issues (and I’ll keep trying), the old patterns of editing have continued and the article is only getting worse.
This ICD seems almost entirely based around a model that involves organizing conferences and then calling and emailing to recruit speakers and attendees. A large number of people will visit this Wikipedia article to find out more about the organization before deciding to pay for a conference or to join to do an internship. What Wikipedia shows to them reads like an advert, links almost exclusively to of pages on the organizations’ websites and seems very likely to have been written by the organization itself. We are doing an enormous disservice to our readers by keeping this page in its current form.
If somebody wants to make a serious effort to improve the article, I will help and will happily reconsider my !vote. But after quite a bit of time trying to raise interest and to get this fixed, I’m skeptical this can be addressed and my decision reflects this fact. —mako๛ 05:18, 12 June 2012 (UTC)
I concluded that although the organization might be notable according to Wikipedia’s policies and although the Wikipedia article about it might be fixable, the pattern of editing gave me no faith that it could be fixed until something changed.
When the article was deleted, things became quiet. Several months later a new article was created — again, by an anonymous user with no other edit history. Although people tend to look closely at previously deleted new pages, this page was created under a different name: “The Institute of Cultural Diplomacy” and was not noticed.
Deleted Wikipedia articles are only supposed to be recreated after they go through a process called deletion review. Because the article was recreated out of this process, I nominated it for what is called speedy deletion under a policy specifically dealing with recreated articles. It was deleted again. Once again, things were quiet.
In January, it seems, the “Inside the ICD website” was threatened with a lawsuit by the ICD and the maintainers of the site took it down with the following message:
Apparently, the ICD is considering filing a lawsuit against this blog and it will now be taken down. We completely forgot about this blog. Let’s hope no one is being sued. Farewell.
On February 25, the Wikipedia article on ICD was recreated — once again out of process and by a user with almost no previous edit history. The next day, I received an email from Mark Donfried. In the message, Donfried said:
Please note that the ICD is completely in favor of fostering open dialogue and discussions, even critical ones, however some of your activities are raising serious questions about the motives behind your actions and some even seem to be motives of sabotage, since they resulted in ICD not having any Wikipedia page at all.
We are deeply concerned regarding these actions of yours, which are causing us considerable damages. As the person who initiated these actions with Wikipedia and member of the board of Wikipedia , we would therefore request your answer regarding our questions below within the next 10 days (by March 6th). If we do not receive your response we will unfortunately have to consider taking further legal actions with these regards against you and other anonymous editors.
I responded to Donfried to say that I did not think it was prudent to speak with him while he was threatening me. Meanwhile, other Wikipedia editors nominated the ICD article for deletion once again and unanimously decided to delete it. And although I did not participate in the discussion, Donfried emailed again with more threats of legal action hours after the ICD article was deleted:
[A]s the case of the ICD and its presentation on the Wikipedia has seriously worsened in recent days, we see no alternative but to forward this case (including all relevant visible and anonymous contributors) to our legal representatives in both USA and Europe/Germany as well as to the authorities and other corresponded organizations in order to find a remedy to this case.
Donfried has made it very clear that his organization really wants a Wikipedia article and that they believe they are being damaged without one. But the fact that he wants one doesn’t mean that Wikipedia’s policies mean he should have one. Anonymous editors in Berlin and in unknown locations have made it clear that they really want a Wikipedia article about the ICD that does not include criticism. Not only do Wikipedia’s policies and principles not guarantee them this, Wikipedia might be hurt as a project when this happens.
The ICD claims to want to foster open dialogue and criticism. I think they sound like a pretty nice group working toward issues I care about personally. I wish them success.
But there seems to be a disconnect between their goals and the actions of both their leader and proponents. Because I used my real name and was skeptical about the organization on discussion pages on Wikipedia, I was tracked down and threatened. Donfried insinuated that I was motivated to “sabotage” his organization and threatened legal action if I do not answer his questions. The timing of his first letter — the day after the ICD page was recreated — means that I was unwilling to act on my commitment to Wikipedia and its policies.
I have no problem with the ICD and I deeply regret being dragged into this whole mess simply because I wanted to improve Wikipedia. That said, Donfried’s threat has scared me off from attempts to improve the ICD articles. I suspect I will not edit ICD pages in Wikipedia in the future.
The saddest part for me is that I recognize that what is in effect bullying is working. There are currently Wikipedia articles about the ICD in many languages. For several years, ICD has had an article on English Wikipedia. For almost all of that period, that article has consisted entirely of universally positive text, without criticism, and has been written almost entirely by anonymous editors who have only contributed to articles related to the ICD.
In terms of the ICD and its article on Wikipedia, I still have hope. I encourage Donfried and his “representatives” to create accounts on Wikipedia with their full names — just like I have. I encourage them to engage in open dialogue in public on the wiki. I encourage them go through deletion review, make any conflicts of interest they have unambiguously clear, and to work with demonstrably non-conflicted editors on Wikipedia to establish notability under Wikipedia’s policies. The result still can be an awesome, neutral, article about their organization. I have offered both advice on how to do this and help in that process in the past. I have faith this can happen and I will be thrilled when it does.
But the general case still worries me deeply. If I can be scared off by threats like these, anybody can. After all, I have friends at the Wikimedia Foundation, a position at Harvard Law School, and am close friends with many of the world’s greatest lawyer-experts on both wikis and cyberlaw. And even I am intimidated into not improving the encyclopedia.
I am concerned by what I believe is the more common case — where those with skin in the game will fight harder and longer than a random Wikipedian. The fact that it’s usually not me on the end of the threat gives me lots of reasons to worry about Wikipedia at a time when its importance and readership continues to grow as its editor-base remains stagnant.
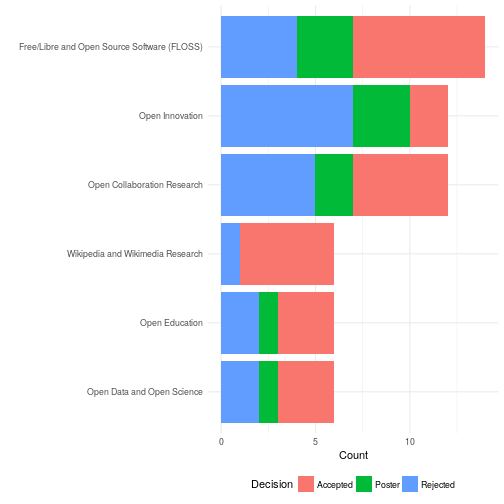
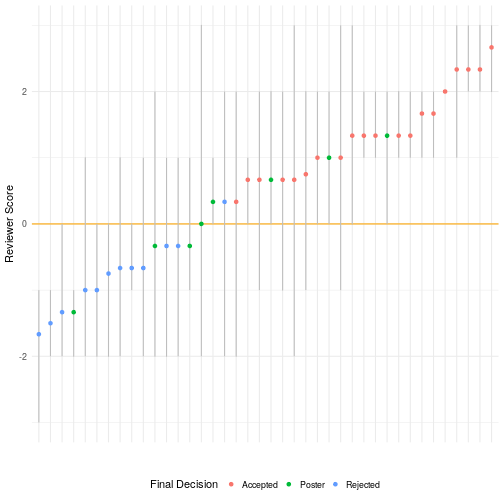
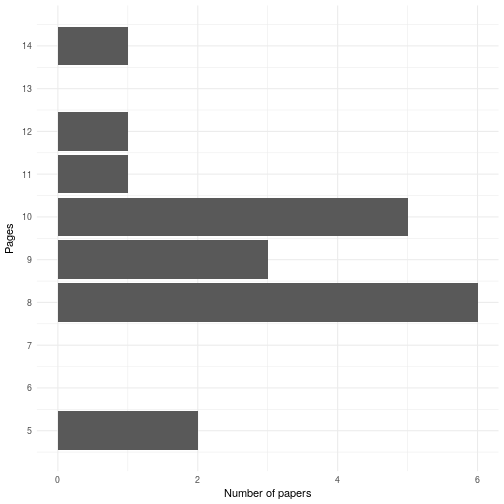 In the end 3 of 20 published papers (15%) were over 10 pages. More surprisingly, 11 of the accepted papers (55%) were below the old 10-page limit. Fears that some have expressed that page limits are the only thing keeping OpenSym from publshing enormous rambling manuscripts seems to be unwarranted—at least so far.
In the end 3 of 20 published papers (15%) were over 10 pages. More surprisingly, 11 of the accepted papers (55%) were below the old 10-page limit. Fears that some have expressed that page limits are the only thing keeping OpenSym from publshing enormous rambling manuscripts seems to be unwarranted—at least so far.