This post was written with Andrés Monroy-Hernández for the Follow the Crowd Research Blog. The post is a summary of a paper forthcoming in Computer-Supported Cooperative Work 2013. You read also read the full paper: The Cost of Collaboration for Code and Art: Evidence from Remixing. It is part of a series of papers I have written with Monroy-Hernández using data from Scratch. You can find the others on my academic website.
Does collaboration result in higher quality creative works than individuals working alone? Is working in groups better for functional works like code than for creative works like art? Although these questions lie at the heart of conversations about collaborative production on the Internet and peer production, it can be hard to find research settings where you can compare across both individual and group work and across both code and art. We set out to tackle these questions in the context of a very large remixing community.
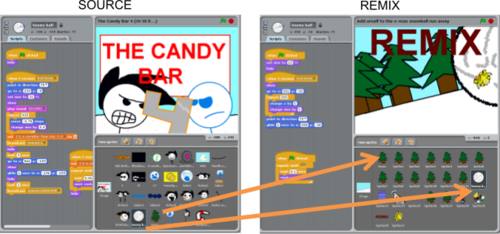
Example of a remix in the Scratch online community, and the project it is based off. The orange arrows indicate pieces which were present in the original and reused in the remix.
Remixing platforms provide an ideal setting to answer these questions. Most support the sharing, and collaborative rating, of both individually and collaboratively authored creative works. They also frequently combine code with artistic media like sound and graphics.
We know that that increased collaboration often leads to higher quality products. For example, studies of Wikipedia have suggested that vandalism is detected and removed within minutes, and that high quality articles in Wikipedia, by several measures, tend to be produced by more collaboration. That said, we also know that collaborative work is not always better — for example, that brainstorming results in less good ideas when done in groups. We attempt to answer this broad question, asked many times before, in the context of remixing: Which is the better description, “the wisdom of crowds” or “too many cooks spoil the broth”? That, fundamentally, forms our paper’s first research question: Are remixes, on average, higher quality than single-authored works?
A number of critics of peer production, and some fans, have suggested that mass collaboration on the Internet might work much better for certain kinds of works. The argument is that free software and Wikipedia can be built by a crowd because they are functional. But more creative works — like music, a novel, or a drawing — might benefit less, or even be hurt by, participation by a crowd. Our second research question tries to get at this possibility: Are code-intensive remixes, higher quality than media-intensive remixes?
We try to answers to these questions using a detailed dataset from Scratch – a large online remixing community where young people build, share, and collaborate on interactive animations and video games. The community was built to support users of the Scratch programming environment: a desktop application with functionality similar to Flash created by the Lifelong Kindergarten Group at the MIT Media Lab. Scratch is designed to allow users to build projects by integrating images, music, sound and other media with programming code. Scratch is used by more than a million, mostly young, users.
Measuring quality is tricky and we acknowledge that there are many ways to do it. In the paper, we rely most heavily a measure of peer ratings in Scratch called loveits — very similar to “likes” on Facebook. We find similar results with several other metrics and we control for the number of views a project receives.
In answering our first research question, we find that remixes are, on average, rated as being of lower quality than works of single authorship. This finding was surprising to us but holds up across a number of alternative tests and robustness checks.
In answering our second question, we find rough support for the common wisdom that remixing tends to be more effective for functional works than for artistic media. The more code-intensive a project is, on average, the closer the gap is between a remix and a work of single authorship. But the more media-intensive a project is, the bigger the gap. You can see the relationships that our model predicts in the graph below.
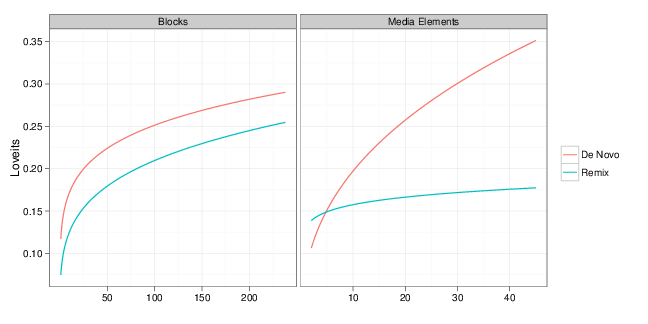
Two plots of estimated values for prototypical projects showing the predicted number of loveits using our estimates. In the left panel, the x-axis varies number of blocks while holding media intensity at the sample median. The right panel varies the number of media elements while holding the number of blocks at the sample median. Ranges for each are from 0 to the 90th percentile.
Both of us are supporters and advocates of remixing. As a result, we were initially a little troubled by our result in this paper. We think the finding suggests an important limit to the broadest claims of the benefit of collaboration in remixing and peer production.
That said, we also reject the blind repetition of the mantra that collaboration is always better — for every definition of “better,” and for every type of work. We think it’s crucial to learn and understand the limitations and challenges associated with remixing and we’re optimistic that this work can influence the design of social media and collaboration systems to help remixing and peer production thrive.
For more, see our full paper, The Cost of Collaboration for Code and Art: Evidence from Remixing.
I was wondering if there was a need to normalize the attention the derived works were getting? As each derived artistic work is now competing for attention the pool of available attention should be shrinking.
I wonder how a metric like number of reuses of an artistic work * number of lovits would compare to the code * loveits? (Or probably forks of code * loveits).
I suppose the real problem is that people get bored of art much faster than they get bored of a useful thing. The second question then be is their a decay function, for loveits for good works as well?
Thanks so much for the great questions, Diane! Here are my attempts at answers:
(1) I agree that its important to take into account increased attention that derived works (or de novo works, for that matter!) might be getting. We add controls for viewership and find that it explains a large portion of the variation. But we find that the basic effects and their relative sizes are the same. So I think we address this issue and find no effect.
(2) In terms of your curiosity about the metric. We did use number of remixes/reuses as an alternative mechanism of generativity and includes all the different combinations you ask about. The results are basically the same because the vast majority of projects that have been remixed were only remixed once. I think we mention this in a footnote. I’m sorry it wasn’t clear. If I recall correctly, we used to have this into the paper and reviewed it based on editor/reviewer feedback and now just reference it in a footnote.
(3) We do not look into a decay function although I think you might well be right! There is some other work studying ccMixter by Jude Yew that has suggested that something quite a lot like this may happen.