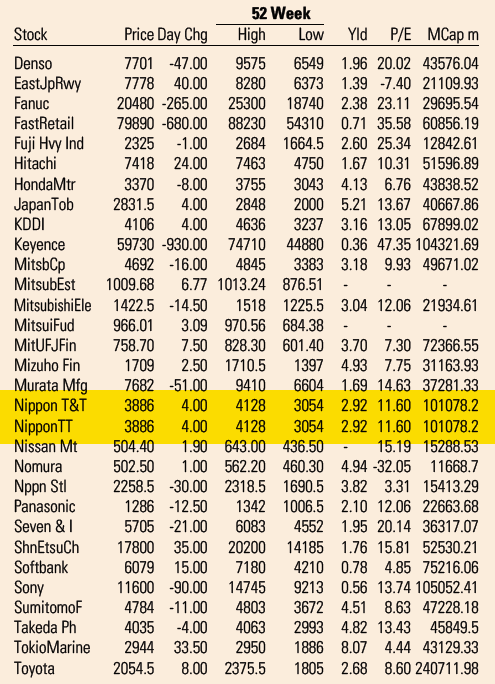
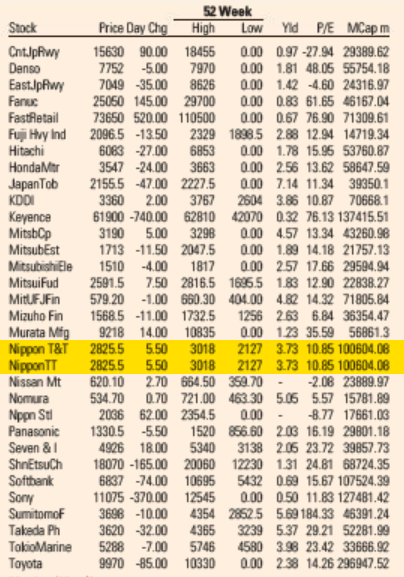
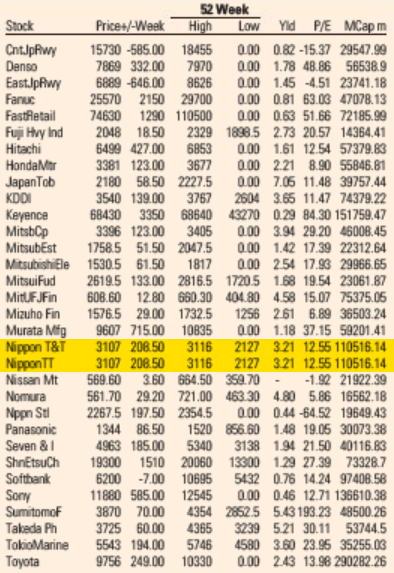
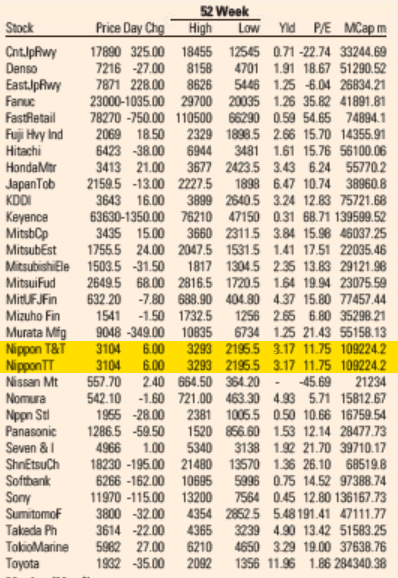
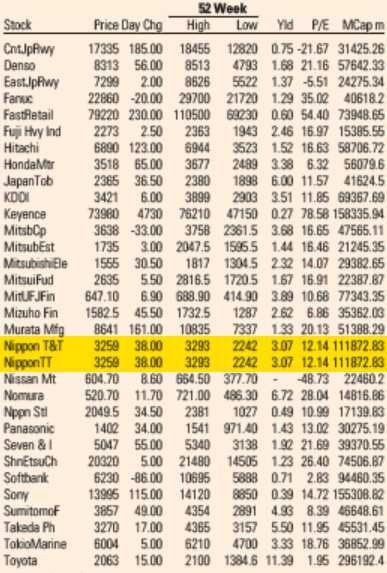
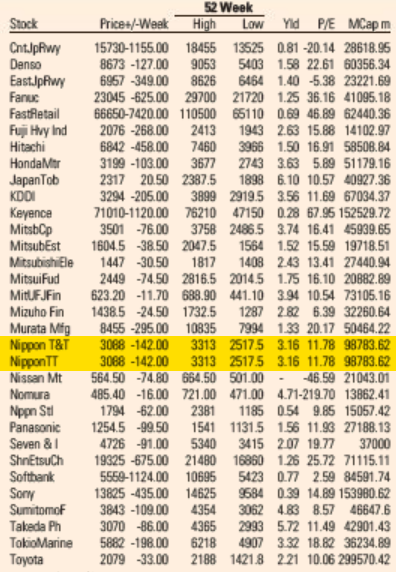
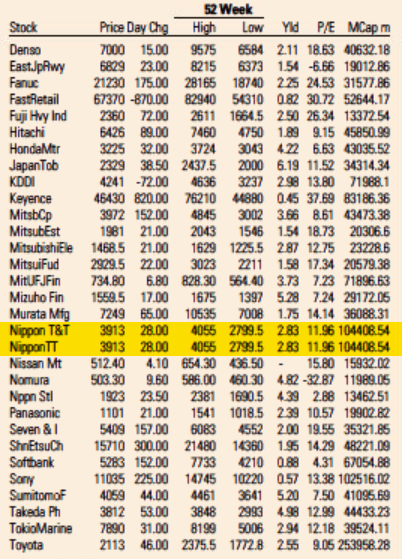
Market Data section of the Financial Times US Edition print edition from May 5, 2021.
If you’ve flipped through printed broadsheet newspapers, you’ve probably seen pages full of tiny text listing prices and other market information for stocks and commodities. And you’ve almost certainly just turned the page. Anybody interested in this market prices today will turn to the internet where these numbers are available in real time and where you don’t need to squint to find what you need. This is presumably why many newspapers have stopped printing these types of pages or dramatically reduced the space devoted to them. Major financial newspapers however—like the Financial Times (FT)—still print multiple pages of market data daily. But does anybody read them?
The answer appears to be “no.” How do I know? I noticed an error in the FT‘s “Market Data” page that anybody looking in the relevant section of the page would have seen. And I have seen it reproduced every single day for the last 18 months.
In early May last year, I noticed that the Japanese telecom giant Nippon Telegraph and Telephone (NTT) was listed twice on the FT‘s list of the 500 largest global companies: once as “Nippon T&T” and also as “Nippon TT.” One right above the other. All the numbers are identical. Clearly a mistake.
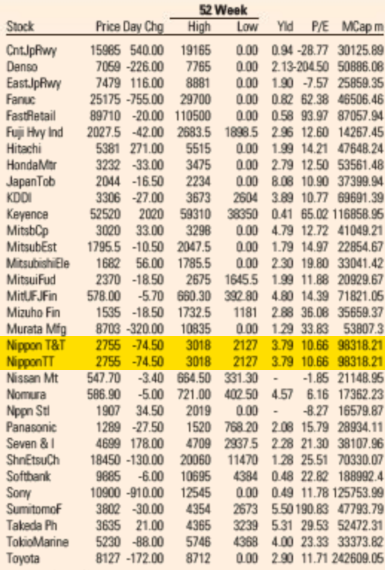
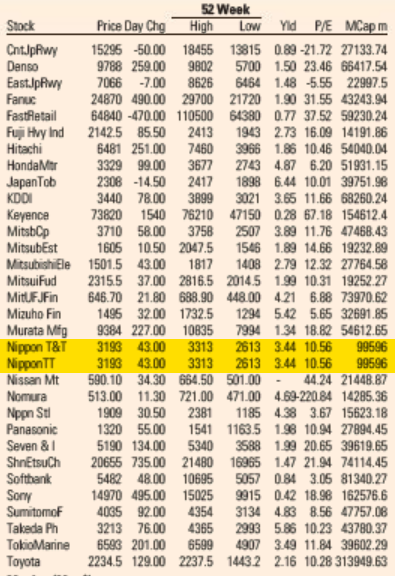
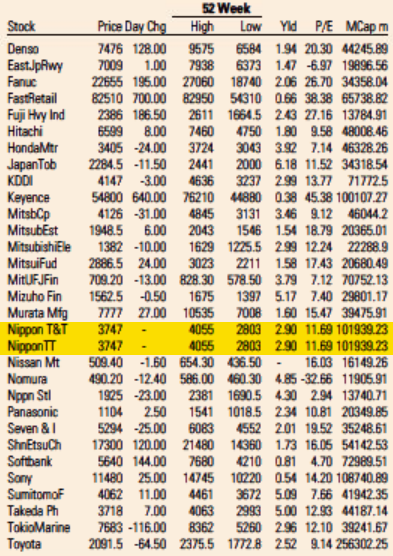
Reproduction of the FT Market Data section showing a subset of Japanese companies from the FT 500 list of global companies. The duplicate lines are highlighted in yellow. This page is from today’s paper (November 26, 2022).
Wondering if it was a one-off error, I looked at a copy of the paper from about a week before and saw that the error did not exist then. I looked at a copy from one day before and saw that it did. Since the issue was apparently recurring, but new at the time, I figured someone at the paper would notice and fix it quickly. I was wrong. It has been 18 months now and the error has been reproduced every single day.
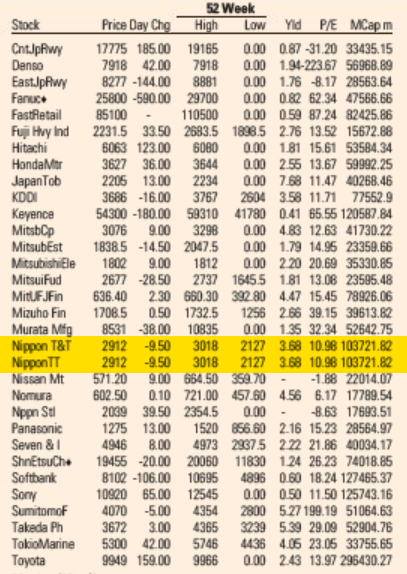
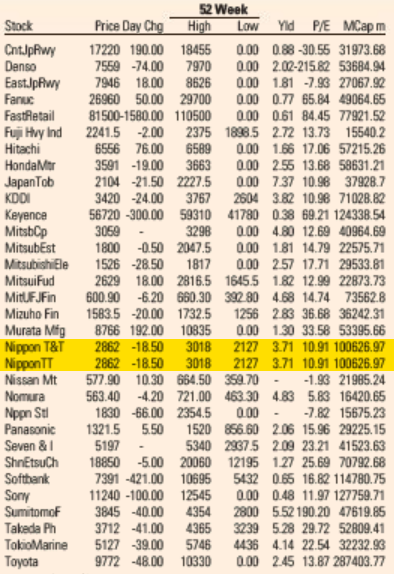
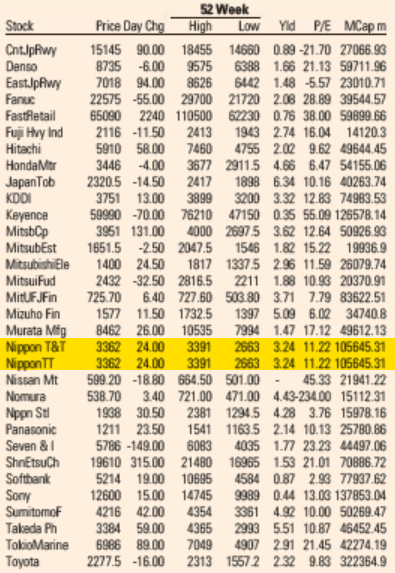
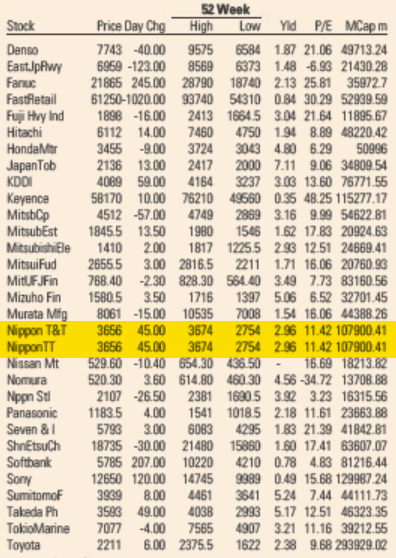
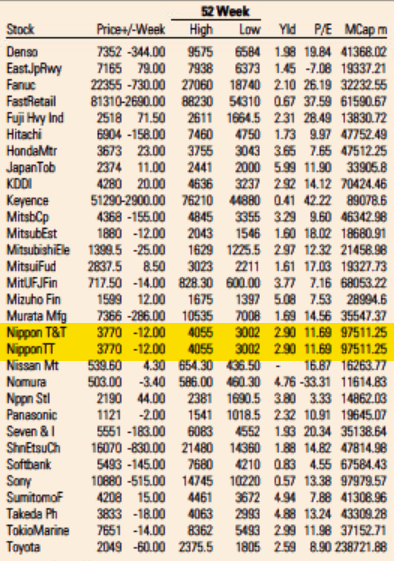
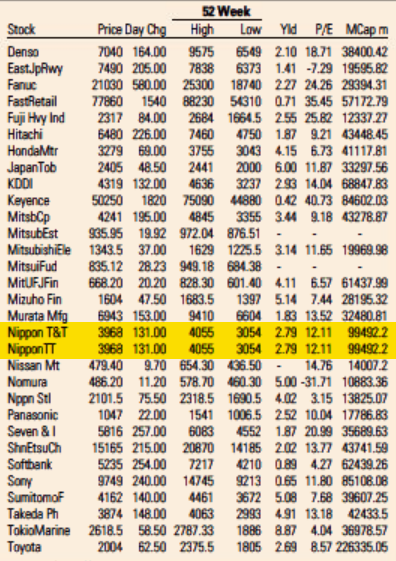
Looking through the archives, it seems that the first day the error showed up was May 5, 2021. I’ve included a screenshot from the electronic paper version from that day—and from the fifth of every month since then (or the sixth if the paper was not printed on the fifth)—that shows that the error is reproduced every day. A quick look in the archives suggests it not only appears in the US edition but also in the UK, European, Asian, and Middle East editions. All of them.
Why does this matter? The FTprints over 112,000 copies of its paper, six days a week. This duplicate line takes up almost no space, of course, so it’s not a big deal on its own. But devoting two full broadsheet pages to market data that is out date as soon as it is printed—much of which nobody appears to be reading—doesn’t seem like a great use of resources. There’s an argument to made that papers like the FT print these pages not because they are useful but because doing so is a signal of the publications’ identities as serious financial papers. But that hardly seems like a good enough reason on its own if nobody is looking at them. It seems well past time for newspapers to stop wasting paper and ink on these pages.
I respect that some people think that printing paper newspapers at all is wasteful when one can just read the material online. Plenty of people disagree, of course. But who will disagree with a call to stop printing material that evidence suggests is not being seen by anybody? If an error this obvious can exist for so long, it seems clear that nobody—not even anybody at the FT itself—is reading it.
Should online communities require people to create accounts before participating?
This question has been a source of disagreement among people who start or manage online communities for decades. Requiring accounts makes some sense since users contributing without accounts are a common source of vandalism, harassment, and low quality content. In theory, creating an account can deter these kinds of attacks while still making it pretty quick and easy for newcomers to join. Also, an account requirement seems unlikely to affect contributors who already have accounts and are typically the source of most valuable contributions. Creating accounts might even help community members build deeper relationships and commitments to the group in ways that lead them to stick around longer and contribute more.
In a new paper published in Communication Research, I worked with Aaron Shaw provide an answer. We analyze data from “natural experiments” that occurred when 136 wikis on Fandom.com started requiring user accounts. Although we find strong evidence that the account requirements deterred low quality contributions, this came at a substantial (and usually hidden) cost: a much larger decrease in high quality contributions. Surprisingly, the cost includes “lost” contributions from community members who had accounts already, but whose activity appears to have been catalyzed by the (often low quality) contributions from those without accounts.
The full citation for the paper is: Hill, Benjamin Mako, and Aaron Shaw. 2020. “The Hidden Costs of Requiring Accounts: Quasi-Experimental Evidence from Peer Production.” Communication Research, 48 (6): 771–95. https://doi.org/10.1177/0093650220910345.
Ever considered doing research about online communities, free culture/software, and peer production full time? It’s PhD admission season and my research group—the Community Data Science Collective—is doing an open-to-anyone Q&A about PhD admissions this Friday November 5th. We’ve got room in the session and its not too late to sign up to join us!
The session will be a good opportunity to hear from and talk to faculty recruiting students to our various programs at the University of Washington, Purdue, and Northwestern and to talk with current and previous students in the group.
The registration deadline for the Q&A session is listed as today but we’ll do what we can to sneak you in even if you register late. That said, please do register ASAP so we can get you the link to the session!
I first started using Debian sometime in the mid 90s and started contributing as a developer and package maintainer more than two decades years ago. My first very first scholarly publication, collaborative work led by Martin Michlmayr that I did when I was still an undergrad at Hampshire College, was about quality and the reliance on individuals in Debian. To this day, many of my closest friends are people I first met through Debian. I met many of them at Debian’s annual conference DebConf.
Given my strong connections to Debian, I find it somewhat surprising that although all of my academic research has focused on peer production, free culture, and free software, I haven’t actually published any Debian related research since that first paper with Martin in 2003!
So it felt like coming full circle when, several days ago, I was able to sit in the virtual DebConf audience and watch two of my graduate student advisees—Kaylea Champion and Wm Salt Hale—present their research about Debian at DebConf21.
Salt presented his masters thesis work which tried to understand the social dynamics behind organizational resilience among free software projects. Kaylea presented her work on a new technique she developed to identifying at risk software packages that are lower quality than we might hope given their popularity (you can read more about Kaylea’s project in our blog post from earlier this year).
And if you’re interested in joining us—perhaps to do more research on FLOSS and/or Debian and/or a graduate degree of your own?—please be in touch with me directly!
The grant will support a bunch of new research to develop and test a theory about the relationship between governance and online community lifecycles. If you’ve been reading this blog for a while, you’ll know that I’ve been involved in a bunch of research to describe how peer production communities tend to follow common patterns of growth and decline as well as a studies that show that many open communities become increasingly closed in ways that deter lots of the kinds contributions that made the communities successful in the first place.
Over the last few years, I’ve worked with Aaron Shaw to develop the outlines of an explanation for why many communities because increasingly closed over time in ways that hurt their ability to integrate contributions from newcomers. Over the course of the work on the CAREER, I’ll be continuing that project with Aaron and I’ll also be working to test that explanation empirically and to develop new strategies about what online communities can do as a result.
In addition to supporting research, the grant will support a bunch of new outreach and community building within the Community Data Science Collective. In particular, I’m planning to use the grant to do a better job of building relationships with community participants, community managers, and others in the platforms we study. I’m also hoping to use the resources to help the CDSC do a better job of sharing our stuff out in ways that are useful as well doing a better job of listening and learning from the communities that our research seeks to inform.
There are many to thank. The proposed work was the direct research of the work I did as the Center for Advanced Studies in the Behavioral Sciences at Stanford where I got to spend the 2018-2019 academic year in Claude Shannon’s old office and talking through these ideas with an incredible range of other scholars over lunch every day. It’s also the product of years of conversations with Aaron Shaw and Yochai Benkler. The proposal itself reflects the excellent work of the whole CDSC who did the work that made the award possible and provided me with detailed feedback on the proposal itself.
I wrote this blog post with Kaylea Champion and a version of this post was originally posted on the Community Data Science Collective blog.
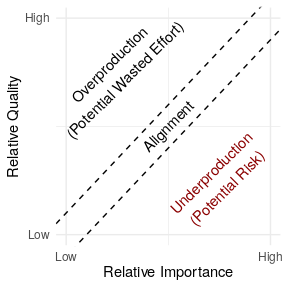
Critical software we all rely on can silently crumble away beneath us. Unfortunately, we often don’t find out software infrastructure is in poor condition until it is too late. Over the last year or so, I have been supporting Kaylea Champion on a project my group announced earlier to measure software underproduction—a term we use to describe software that is low in quality but high in importance.
Underproduction reflects an important type of risk in widely used free/libre open source software (FLOSS) because participants often choose their own projects and tasks. Because FLOSS contributors work as volunteers and choose what they work on, important projects aren’t always the ones to which FLOSS developers devote the most attention. Even when developers want to work on important projects, relative neglect among important projects is often difficult for FLOSS contributors to see.
Conceptual diagram showing how our conception of underproduction relates to quality and importance of software.
In the paper, we describe a general approach for detecting “underproduced” software infrastructure that consists of five steps: (1) identifying a body of digital infrastructure (like a code repository); (2) identifying a measure of quality (like the time to takes to fix bugs); (3) identifying a measure of importance (like install base); (4) specifying a hypothesized relationship linking quality and importance if quality and importance are in perfect alignment; and (5) quantifying deviation from this theoretical baseline to find relative underproduction.
To show how our method works in practice, we applied the technique to an important collection of FLOSS infrastructure: 21,902 packages in the Debian GNU/Linux distribution. Although there are many ways to measure quality, we used a measure of how quickly Debian maintainers have historically dealt with 461,656 bugs that have been filed over the last three decades. To measure importance, we used data from Debian’s Popularity Contest opt-in survey. After some statistical machinations that are documented in our paper, the result was an estimate of relative underproduction for the 21,902 packages in Debian we looked at.
One of our key findings is that underproduction is very common in Debian. By our estimates, at least 4,327 packages in Debian are underproduced. As you can see in the list of the “most underproduced” packages—again, as estimated using just one more measure—many of the most at risk packages are associated with the desktop and windowing environments where there are many users but also many extremely tricky integration-related bugs.
These 30 packages have the highest level of underproduction in Debian according to our analysis.
We hope these results are useful to folks at Debian and the Debian QA team. We also hope that the basic method we’ve laid out is something that others will build off in other contexts and apply to other software repositories.
Paper Citation: Kaylea Champion and Benjamin Mako Hill. 2021. “Underproduction: An Approach for Measuring Risk in Open Source Software.” In Proceedings of the IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER 2021). IEEE.
Contact Kaylea Champion (kaylea@uw.edu) with any questions or if you are interested in following up.
I served as a director and as a voting member of the Free Software Foundation for more than a decade. I left both positions over the last 18 months and currently have no formal authority in the organization.
So although it is now just my personal opinion, I will publicly add my voice to the chorus of people who are expressing their strong opposition to Richard Stallman’s return to leadership in the FSF and to his continued leadership in the free software movement. The current situation makes me unbelievably sad.
I stuck around the FSF for a long time (maybe too long) and worked hard (I regret I didn’t accomplish more) to try and make the FSF better because I believe that it is important to have voices advocating for social justice inside our movement’s most important institutions. I believe this is especially true when one is unhappy with the existing state of affairs. I am frustrated and sad that I concluded that I could no longer be part of any process of organizational growth and transformation at FSF.
I have nothing but compassion, empathy, and gratitude for those who are still at the FSF—especially the staff—who are continuing to work silently toward making the FSF better under intense public pressure. I still hope that the FSF will emerge from this as a better organization.
In May 2019, my research group was invited to give short remarks on the impact of Janet Fulk and Peter Monge at the International Communication Association‘s annual meeting as part of a session called “Igniting a TON (Technology, Organizing, and Networks) of Insights: Recognizing the Contributions of Janet Fulk and Peter Monge in Shaping the Future of Communication Research.”
Youtube: Mako Hill @ Janet Fulk and Peter Monge Celebration at ICA 2019
I gave a five-minute talk on Janet and Peter’s impact to the work of the Community Data Science Collective by unpacking some of the cryptic acronyms on the CDSC-UW lab’s whiteboard as well as explaining that our group has a home in the academic field of communication, in no small part, because of the pioneering scholarship of Janet and Peter. You can view the talk in WebM or on Youtube.
Introducing new technology into a work place is often disruptive, but what if your work was also completely mediated by technology? This is exactly the case for the teams of volunteer moderatorswho work to regulate content and protect online communities from harm. What happens when the social media platforms these communities rely on change completely? How do moderation teams overcome the challenges caused by new technological environments? How do they do so while managing a “brand new” community with tens of thousands of users?
For a new study that will be published in CSCW in November, we interviewed 14 moderators of 8 “subreddit” communities from the social media aggregation and discussion platform Reddit to answer these questions. We chose these communities because each community had recently adopted the real-time chat platform Discord to support real-time chat in their community. This expansion into Discord introduced a range of challenges—especially for the moderation teams of large communities.
We found that moderation teams of large communities improvised their own creative solutions to challenges they faced by building bots on top of Discord’s API. This was not too shocking given that APIs and bots are frequently cited as tools that allow innovation and experimentation when scaling up digital work. What did surprise us, however, was how important moderators’ past experiences were in guiding the way they used bots. In the largest communities that faced the biggest challenges, moderators relied on bots to reproduce the tools they had used on Reddit. The moderators would often go so far as to give their bots the names of moderator tools available on Reddit. Our findings suggest that support for user-driven innovation is important not only in that it allows users to explore new technological possibilities but also in that it allows users to mine their past experiences to introduce old systems into new environments.
What Challenges Emerged in Discord?
Discord’s text channels allow for more natural, in the moment conversations compared to Reddit. In Discord, this social aspect also made moderation work much more difficult. One moderator explained:
“It’s kind of rough because if you miss it, it’s really hard to go back to something that happened eight hours ago and the conversation moved on and be like ‘hey, don’t do that.’ ”
Moderators we spoke to found that the work of managing their communities was made even more difficult by their community’s size:
On the day to day of running 65,000 people, it’s literally like running a small city…We have people that are actively online and chatting that are larger than a city…So it’s like, that’s a lot to actually keep track of and run and manage.”
The moderators of large communities repeatedly told us that the tools provided to moderators on Discord were insufficient. For example, they pointed out tools like Discord’s Audit Log was inadequate for keeping track of the tens of thousands of members of their communities. Discord also lacks automated moderation tools like the Reddit’s Automoderator and Modmail leaving moderators on Discord with few tools to scale their work and manage communications with community members.
How Did Moderation Teams Overcome These Challenges?
The moderation teams we talked with adapted to these challenges through innovative uses of Discord’s API toolkit. Like many social media platforms, Discord offers a public API where users can develop apps that interact with the platform through a Discord “bot.” We found that these bots play a critical role in helping moderation teams manage Discord communities with large populations.
Guided by their experience with using tools like Automoderator on Reddit, moderators working on Discord built bots with similar functionality to solve the problems associated with scaled content and Discord’s fast-paced chat affordances. This bots would search for regular expressions and URLs that go against the community’s rules:
“It makes it so that rather than having to watch every single channel all of the time for this sort of thing or rely on users to tell us when someone is basically running amuck, posting derogatory terms and terrible things that Discord wouldn’t catch itself…so it makes it that we don’t have to watch every channel.”
Bots were also used to replace Discord’s Audit Log feature with what moderators referred to often as “Mod logs”—another term borrowed from Reddit. Moderators will send commands to a bot like “!warn username” to store information such as when a member of their community has been warned for breaking a rule and automatically store this information in a private text channel in Discord. This information helps organize information about community members, and it can be instantly recalled with another command to the bot to help inform future moderation actions against other community members.
Finally, moderators also used Discord’s API to develop bots that functioned virtually identically to Reddit’s Modmail tool. Moderators are limited in their availability to answer questions from members of their community, but tools like the “Modmail” helps moderation teams manage this problem by mediating communication to community members with a bot:
“So instead of having somebody DM a moderator specifically and then having to talk…indirectly with the team, a [text] channel is made for that specific question and everybody can see that and comment on that. And then whoever’s online responds to the community member through the bot, but everybody else is able to see what is being responded.”
The tools created with Discord’s API — customizable automated content moderation, Mod logs, and a Modmail system — all resembled moderation tools on Reddit. They even bear their names! Over and over, we found that moderation teams essentially created and used bots to transform aspects of Discord, like text channels into Mod logs and Mod Mail, to resemble the same tools they were using to moderate their communities on Reddit.
What Does This Mean for Online Communities?
We think that the experience of moderators we interviewed points to a potentially important underlooked source of value for groups navigating technological change: the potent combination of users’ past experience combined with their ability to redesign and reconfigure their technological environments. Our work suggests the value of innovation platforms like APIs and bots is not only that they allow the discovery of “new” things. Our work suggests that these systems value also flows from the fact that they allow the re-creation of the the things that communities already know can solve their problems and that they already know how to use.
Mika and I recently spent two weeks biking home to Seattle from our year in Palo Alto. The route was ~1400 kilometers and took us past 10 volcanoes and 4 hot springs.
Route of our bike trip from Davis, CA to Oregon City, OR. An elevation profile is also shown.
To my delight, the route also took us past at least 8 hairdressers with supposedly funny pun names! Plus two in Oakland on our way out.
I’d like to use “sinonym” as another word for an immoral act. Or perhaps to refer to the Chinese name for something. Sadly, I think it might just be another word for another word.
Informal online learning communities are one of the most exciting and successful ways to engage young people in technology. As the most successful example of the approach, over 40 million children from around the world have created accounts on the Scratch online community where they learn to code by creating interactive art, games, and stories. However, despite its enormous reach and its focus on inclusiveness, participation in Scratch is not as broad as one would hope. For example, reflecting a trend in the broader computing community, more boys have signed up on the Scratch website than girls.
In a recently published paper, I worked with several colleagues from the Community Data Science Collective to unpack the dynamics of unequal participation by gender in Scratch by looking at whether Scratch users choose to share the projects they create. Our analysis took advantage of the fact that less than a third of projects created in Scratch are ever shared publicly. By never sharing, creators never open themselves to the benefits associated with interaction, feedback, socialization, and learning—all things that research has shown participation in Scratch can support.
Overall, we found that boys on Scratch share their projects at a slightly higher rate than girls. Digging deeper, we found that this overall average hid an important dynamic that emerged over time. The graph below shows the proportion of Scratch projects shared for male and female Scratch users’ 1st created projects, 2nd created projects, 3rd created projects, and so on. It reflects the fact that although girls share less often initially, this trend flips over time. Experienced girls share much more than often than boys!
Proportion of projects shared by gender across experience levels, measured as the number of projects created, for 1.1 million Scratch users. Projects created by girls are less likely to be shared than those by boys until about the 9th project is created. The relationship is subsequently reversed.
We unpacked this dynamic using a series of statistical models estimated using data from over 5 million projects by over a million Scratch users. This set of analyses echoed our earlier preliminary finding—while girls were less likely to share initially, more experienced girls shared projects at consistently higher rates than boys. We further found that initial differences in sharing between boys and girls could be explained by controlling for differences in project complexity and in the social connectedness of the project creator.
Another surprising finding is that users who had received more positive peer feedback, at least as measured by receipt of “love its” (similar to “likes” on Facebook), were less likely to share their subsequent projects than users who had received less. This relation was especially strong for boys and for more experienced Scratch users. We speculate that this could be due to a phenomenon known in the music industry as “sophomore album syndrome” or “second album syndrome”—a term used to describe a musician who has had a successful first album but struggles to produce a second because of increased pressure and expectations caused by their previous success
Online anonymity often gets a bad rap and complaints about antisocial behavior from anonymous Internet users are as old as the Internet itself. On the other hand, research has shown that many Internet users seek out anonymity to protect their privacy while contributing things of value. Should people seeking to contribute to open collaboration projects like open source software and citizen science projects be required to give up identifying information in order to participate?
I was part of a team led by Nora McDonald that conducted a two-part study to better understand how open collaboration projects balance the threats of bad behavior with the goal of respecting contributors’ expectations of privacy. First, we interviewed eleven people from five different open collaboration “service providers” to understand what threats they perceive to their projects’ mission and how these threats shape privacy and security decisions when it comes to anonymous contributions. Second, we analyzed discussions about anonymous contributors on publicly available logs of the English language Wikipedia mailing list from 2010 to 2017.
In the interview study, we identified three themes that pervaded discussions of perceived threats. These included threats to:
community norms, such as harrassment;
sustaining participation, such as loss of or failure to attract volunteers; and
contribution quality, low-quality contributions drain community resources.
We found that open collaboration providers were most concerned with lowering barriers to participation to attract new contributors. This makes sense given that newbies are the lifeblood of open collaboration communities. We also found that service providers thought of allowing anonymous contributions as a way of offering low barriers to participation, not as a way of helping contributors manage their privacy. They imagined that anonymous contributors who wanted to remain in the community would eventually become full participants by registering for an account and creating an identity on the site. This assumption was evident in policies and technical features of collaboration platforms that barred anonymous contributors from participating in discussions, receiving customized suggestions, or from contributing at all in some circumstances. In our second study of the English language Wikipedia public email listserv, we discovered that the perspectives we encountered in interviews also dominated discussions of anonymity on Wikipedia. In both studies, we found that anonymous contributors were seen as “second-class citizens.
This is not the way anonymous contributors see themselves. In a study we published two years ago, we interviewed people who sought out privacy when contributing to open collaboration projects. Our subjects expressed fears like being doxed, shot at, losing their job, or harassed. Some were worried about doing or viewing things online that violated censorship laws in their home country. The difference between the way that anonymity seekers see themselves and the way they are seen by service providers was striking.
One cause of this divergence in perceptions around anonymous contributors uncovered by our new paper is that people who seek out anonymity are not able to participate fully in the process of discussing and articulating norms and policies around anonymous contribution. People whose anonymity needs means they cannot participate in general cannot participate in the discussions that determine who can participate.
We conclude our paper with the observation that, although social norms have played an important role in HCI research, relying on them as a yardstick for measuring privacy expectations may leave out important minority experiences whose privacy concerns keep them from participating in the first place. In online communities like open collaboration projects, social norms may best reflect the most privileged and central users of a system while ignoring the most vulnerable
The award itself is a plush fish with a parasitic lamprey attached to it.
As of yesterday, I’m officially a research symbiont! A committee of health scientists saw fit to give me a Research Symbiont Award which is awarded annually to “a scientist working in any field who has shared data beyond the expectations of their field.” The award was announced at Pacific Symposium on Biocomputing and came with a trip to Hawaii (which I couldn’t take!) and the awesome plush fish with a parasitic lamprey shown in the picture.
Sharing data in ways that are useful to others is a ton of work. It takes more time than you might imagine to prepare, polish, validate, test, and document data for others to use. I think I spent more time working with Andrés Monroy-Hernández on the Scratch Research Dataset than I have any single empirical paper! Although I spent the time doing it because I think it’s an important way to contribute to science, recognition in the form of an award—and a cute stuffed parasitic fish—is super appreciated as well!