The first version of this paper was written to an accepted talk given at Linuxtag 2005 given in Karlsruhe, Germany.
Introduction
The explosive growth of free and open source software over the
last decade has been mirrored by an equally explosive growth in the
ambitiousness of free software projects in choosing and tackling
problems. The free software movement approaches these large
problems with more code and with more expansive communities than
was thinkable a decade ago. Example of these massive projects
include desktop environments — like GNOME and KDE — and
distributions like Debian, RedHat, and Gentoo.
These projects are leveraging the work of thousands of
programmers — both volunteer and paid — and are
producing millions of lines of code. Their software is being used
by millions of users with diverse sets of needs. This paper focuses
on two major effects of this situation:
The communities that free software projects — and in
particular large projects — serve are increasingly diverse.
It is becoming increasingly difficult for a single large project to
release any single product that can cater to all of its potential
users.
It's becoming increasingly difficult to reproduce these large
projects. While reproducing entire project is impossible for small
groups of hackers, it is often not even possible for small groups
to even track and maintain a fork of a large project over time.
Taken together, these facts imply an increasingly realized free
software community in which programmers frequently derive but where
traditional forking is often untenable. "Forks," as they are
traditionally defined, must be improved upon. Communities around
large free software projects must be smarter about the process of
derivation than they have been in the past.
We are already seeing this with GNU/Linux distributions. New
distributions are rarely built from scratch today. Instead, they
adapted from and built on top of the work of existing projects. As
projects and user-bases grow, these derived distributions are
increasingly common. Most of what I describe in this essay are
tools and experiences of derived distributions.
Software makers must pursue the idea of an ecosystem of free software projects and
products that have forked but that maintain a close relationship as
they develop parallelly and symbiotically. To do this, developers
should:
Break down the process of derivation into a set of different
types of customization and derivation and prioritize methods of
derivation.
Create and foster social solutions to the social aspects of the
derivation problem.
Build and use new tools specifically designed to coordinate
development of software in the context of an ecosystem of
projects.
Distribute and utilize distributed version control tools with an
emphasis on maintaining differences over time.
This paper is an early analysis of this set of problems. As
such, it is highly focused on the experience of the Ubuntu project
and its existence as a derived Debian distribution. It also pulls
from my experience with Debian-NP and the Custom Debian
Distribution (CDD) community. Since I participate in both the
Ubuntu and CDD projects, these are areas that I can discuss with
some degree of knowledge and experience.
"Fork" Is A Four Letter Word
The act of taking the code for a free software project and
bifurcating it to create a new project is called "forking." There
have been a number of famous forks in free software history. One of
the most famous was the schism that led to the parallel development
of two versions of the Emacs text editor: GNU Emacs and XEmacs.
This schism persists to this day.
Some forks, like Emacs and XEmacs, are permanent. Others are
relatively short lived. An example of this is the GCC project which
saw two forks — EGCS and PGCC — that both eventually
merged back into GCC. Forking can happen for any number of reasons.
Often developers on a project develop political or personal
differences that keep them from continuing to work together. In
some cases, maintainers become unresponsive and other developers
fork to keep the software alive.
Ultimately though, most forks occur because people do not agree
on the features, the mechanisms, or the technology at the core of a
project. People have different goals, different problems, and want
different tools. Often, these goals, problems and tools are similar
up until a certain point before the need to part ways becomes
essential.
A fork occurs on the level of code but a fork is not merely
— or even primarily — technical. Many projects create
"branches." Branches are alternative versions of a piece of
software used to experiment with intrusive or unstable features and
fixes. Forks are distinguished from branches both in that they are
often more significant departures from a technical perspective
(i.e., more lines of code have been changed and/or the changes are
more invasive or represent a more fundamental rethinking of the
problem) and in that they are bifurcations defined in social and
political terms. Branches involve a single developer or community of
developers — even if it does boil down to distinct subgroups
within a community — whereas forks are separate projects.
Forking has historically been viewed as a bad thing in free
software communities: they are seen to stem from people's inability
to work together and have ended in reproduction of work. When I
published the first version of the Free Software
Project Management HOWTO more than four years ago, I included a
small subsection on forking which described the concept to future
free software project leaders with this text:
The short version of the fork section is, don't do them. Forks
force developers to choose one project to work with, cause nasty
political divisions, and redundancy of work.
In the best situations, a
fork means that two groups of people need to go on developing
features and doing work they would ordinarily do in addition to tracking the forked
project and having to hand-select and apply features and fixes to
their own code-base. This level of monitoring and constant
comparison can be extremely difficult and time-consuming. The
situation is not helped substantially by traditional source control
tools like diff, patch, CVS and Subversion which are not optimized
for this task. The worse (and much more common) situation occurs
when two groups go about their work ignorant or partially ignorant
of the code being cut on the other side of the fork. Important
features and fixes are implemented twice — differently and
incompatibly.
The most substantial bright side to these drawbacks is that the
problems associated with forking are so severe and notorious that,
in most cases, the threat of a fork is enough to force maintainers
to work out solutions that keep the fork from happening in the
first place.
Finally, it is worth pointing out that fork is something of a
contested term. Because definitions of forks involve, to one degree
or another, statements about the political, organization, and
technical distinctions between projects, bifurcations that many
people call branches or parallel trees are described by others as
forks. Recently, fueled by the advent of distributed version
control systems, the definition of what is and is not a fork has
become increasingly unclear. In part due to the same systems, the
benefits and drawbacks of what is increasingly problematically
called forking is equally debatable.
Case Study
In my introduction, I described how the growing scope of free
software projects and the rapidly increasingly size and diversity
of user communities is spearheading the need for new type of
derivation that avoids, as best as possible, the drawbacks of
forking. Nowhere is this more evident than in the largest projects
with the broadest scope: a small group of projects that includes
operating system distributions.
The Debian Project
The Debian project is by many counts the largest free software
distribution in terms of code. It is the also, arguably, the
largest free software project in terms of the number of volunteers.
Debian includes more than 15,000 packages and the work of well over
1,000 official volunteers and many more contributors without
official membership. Projects without Debian's massive volunteer
base cannot replicate what Debian has accomplished; they can rarely
hope to even maintain what Debian has produced.
At the time that this paper was written, Distrowatch lists 129
distributions based on Debian[1] — most of them are currently active
to varying degrees. Each distribution represents at least one
person — and in most cases a community of people — who
disagreed with Debian's vision or direction strongly enough to want
to create a new distribution and who had the technical capacity to
follow through with this goal. Despite Debian's long-standing
slogan — "the universal operating system" — the fact
that the Debian project has become the fastest growing operating
system while spawning so many derivatives is testament to the fact
that, as far as software is concerned, one size can not fit all.[2]
Organizationally, Debian derivers are located both inside and
outside of the Debian project. A group of derivers working within
the Debian project has labeled themselves "Custom Debian
Distributions" and has created nearly a dozen projects customizing
and deriving from Debian for specific groups of users including
non-profit organization, the medical community, lawyers, children
and many others.[3]
These projects build on the core Debian distribution and the
canonical archive from within the organizational and political
limits of the Debian project and constantly seek to minimize the
delta by focusing on less invasive changes and by advancing
creative ways of building the ability to alter the core Debian code
base through established and policy compliant procedures.
A second group of Debian customizers includes those working
outside of the Debian project organizationally. Notable among this
list are (in alphabetical order) Knoppix, Libranet, Linspire
(formerly Lindows), Progeny, MEPIS, Ubuntu, Userlinux, and Xandros.
With its strong technological base, excellent package management,
wide selection of packages to choose from, and strong commitment to
software freedom which ensures derivability, Debian provides an
ideal point from which to create a GNU/Linux distribution.
Ubuntu
The Ubuntu project was started by Mark Shuttleworth in April
2004 and the first version was built almost entirely by a small
group of a Debian developers employed by Shuttleworth's company
Canonical Limited.[4]
It was released to the world in late 2004. The second version was
released six months later in April 2005. The goals of Ubuntu are to
provide a distribution based on a subset of Debian with:
Regular and predictable releases — every six months with
support for eighteen months.
An emphasis on free software that will maintain the derivability
of the distribution.
An emphasis on usability and a consistent desktop vision. As an
example, this has translated into less questions in the installer
and a default selection and configuration of packages that is
usable for most desktop users "out of the box."
The Ubuntu project provides an interesting example of a project
that aims to derive from Debian to an extensive degree. Ubuntu made
code-level changes to nearly 1300 packages in Debian at the time
that this paper was written and the speed of changes will not
decelerate with time; the total number of changes and the total
size of the delta will grow.[5] The changes that Ubuntu makes are
primarily of the most intrusive kind — changes to the code
itself.
That said, the Ubuntu project is explicit about the fact that it
could not exist without the work done by the Debian
project.[6]
More importantly, Ubuntu explains that it cannot continue to
provide the complete set of packages that its users depend on
without the ongoing work by the Debian project. Even though Ubuntu
has made changes to the nearly 1300 packages, this is less than ten
percent of the total packages shipped in Ubuntu and pulled from
Debian.
Scott James Remnant, a prominent Debian developer and a hacker
on Ubuntu who works for Canonical Ltd., described the situation
this way on his web log to introduce the Ubuntu development
methodology in the week after the first public announcement of
Canonical and Ubuntu:[7]
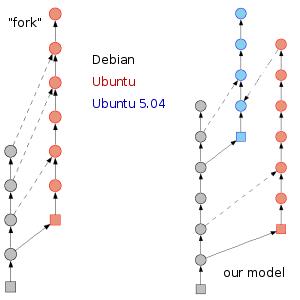
I don't think Ubuntu is a "fork" of Debian, at least not in the
traditional sense. A fork suggests that at some point we go our
separate way from Debian and then occasionally merge in changes as
we carry on down our own path.
Our model is quite different; every six months we take a
snapshot of Debian's unstable distribution, apply any outstanding
patches from our last release to it and spend a couple of months
testing and bug-fixing it.
One thing that should be obvious from this is that our job is a
lot easier if Debian takes all of our changes. The model actually
encourages us to give back to Debian.
That's why from the very first day we started fixing bugs we
began sending the patches
back to Debian through the BTS. Not only will it make our job so
much easier when we come to freeze for "hoary", our next release,
but it's exactly what every derivative should do in the first
place.
There is some debate on the degree to which Ubuntu developers
have succeeded in accomplishing the goals laid out by Remnant.
Ubuntu has filed hundreds of patches in the bug tracking system but
it has also run into problems in deciding what constitutes something that should
be fed back to Debian. Many changes are simply not relevant to
Debian developers. For example, they may include changes to a
package in response to another change made in another package in
Ubuntu that will not or has not been taken by Debian. In many other
cases, the best action in regards to a particular change, a
particular package, and a particular upstream Debian developer is
simply unclear.
The Ubuntu project's track record in working constructively with
Debian is, at the moment, a mixed one. While an increasingly large
number of Debian developers are maintaining their packages actively
within both projects, many in both Debian and Ubuntu feel that
Ubuntu has work left to do in living up to its own goal of a
completely smooth productive relationship with Debian.
That said, the importance of the goals described by Remnant in
the context of of the Ubuntu development model cannot be
overstated. Every line of delta between Debian and Ubuntu has a
cost for Ubuntu developers. Technology, social practices, and wise
choices may reduce that cost but it cannot eliminate it. The
resources that Ubuntu can bring to bear upon the problem of
building a distribution are limited — far more limited than
Debian's. As a result, there is a limit to how far Ubuntu can
diverge; it is always in Ubuntu's advantage to minimize the delta
where possible.
Applicability
Ubuntu and Debian are distributions and — as such —
operate on a different scale than the vast majority of free
software projects. They include more code and more people. As a
result, there are questions as to whether the experiences and
lessons learned from these projects are particularly applicable to
the experience of smaller free software projects.
Clearly, because of the difficulties associated with forking
massive amount of code and the problems associated with duplicating
the work of large volunteer bases, distributions are forced into
finding a way to balance the benefits and drawbacks of forking.
However, while the need is stronger and more immediate in larger
projects, the benefits of their solutions will often be fully
transferable.
Clearly, modifiability of free software to better fit the needs
of its users lies at the heart of the free software movement's
success. However, while modification usually comes in the form of
collaboration on a single code-base, this is a function of
limitations in software development methodologies and tools rather
than the best response to the needs or desires of users or
developers.
I believe that the fundamental advantage of free software in the
next decade will be in the growing ability of any single free
software project to be multiple things to multiple users
simultaneously. This will translate into the fact that, in the next
ten years, technology and social processes will evolve, so that
forking is increasingly less of a bad thing. Free software
development methodology will become less dependent on a single
project and begin to emphasize parallel development within an
ecosystem of related projects. The result is that free software
projects will gain a competitive advantage over propriety software
projects through their ability to better serve the increasingly
diverse needs of increasingly large and increasingly diverse
user-bases. Although it sounds paradoxical today, more projects
will derive and less redundant code will be written.
Projects more limited in code and scope may use the tools and
methods described in the remainder of this paper in different
combinations, in different ways, and to different degrees than the
examples around distributions introduced here. Different projects
with different needs will find that certain solutions work better
than others. Because communities of the size of Debian are
difficult to fork in a way that is beneficial to any party, it is
in these communities that the technology and development
methodologies are first emerging. With time, these strategies and
tools will find themselves employed productively in a wide variety
of projects with a broad spectrum of sizes, needs, scopes and
descriptions.
Balancing Forking With Collaboration
Derivation and Problem Analysis
The easiest step in creating a productive derivative software
project is to break down the problems of derivations into a series
of different classes of modification. Certain types of modification
are more easily done and are intrinsically more maintainable.
In the context of distributions, the problem of derivation can
be broken down into the following types of changes (sorted roughly
according to the intrusiveness inherent in solving the problem and
the severity of the long-term maintainability problems that they
introduce):
Selection of individual pieces of software;
Changes to the way that packages are installed or run (e.g., in
a Live CD type environment or using a different installer);
Configuration of different pieces of software;
Changes made to the actual software package (made on the level
of changes to the packages code);
By breaking down the problem in this way, Debian derivers have
been able to approach derivation in ways that focus energy on the
less intrusive problems first.
The first area that Ubuntu focused on was selecting a subset of
packages that Ubuntu would support. Ubuntu selected and supports
approximate 2,000 packages. These became the main component in Ubuntu. Other
packages in Debian were included in a separate section of the
Ubuntu archive called universe but were not guaranteed
to be supported with bug or security fixes. By focusing on a small
subset of packages, the Ubuntu team was able to select a
maintainable subsection of the Debian archive that they could
maintain over time.
The most simple derived distributions — often working
within the Debian project as CDDs but also including projects like
Userlinux — are merely lists of packages and do nothing
outside of package selection. The installation of lists of packages
and the maintenance of those lists over time can be aided through
the creation of what are called metapackages: empty packages with long
lists of "dependencies."
The second item, configuration changes, is also relatively
low-impact. Focusing on moving as many changes as possible into the
realm of configuration changes is a sustainable strategy that
derivers working within the Debian project intent on a single
code-base have pursued actively. Their idea is that rather than
forking a piece of code due to disagreement in how the program
should work, they can leave the code intact but add the
ability to work in a
different way to the software. This alternate functionality is made
toggleable through a configuration change in the same manner that
applications are configured through questions asked at install
time. Since the Debian project has a unified package configuration
framework called Debconf, derivers are able to configure an entire
system in a highly centralized manner.[8] This is not unlike RedHat's Kickstart
although the emphasis is on maintenance of those configuration
changes over the life and evolution of the package; Kickstart is
focused merely on installation of the package.
A third type of configuration is limited to changes in the
environment through which a system is run or installed. One is
example is Progeny's Anaconda-based Debian installer which provides
an alternate installer but results in an identical system. Another
example is the Knoppix project which is famous for its "Live CD"
environments. While, Knoppix makes a wide range of invasive changes
that span all items in my list above, other Live CD projects,
including Ubuntu's "Casper" project, are much closer to an
alternate shell through which the same code is run.
Because these three methods are relatively non-invasive, they
are reasonable strategies for small teams and individuals working
on creating a derived distribution. However, many desirable changes
— and in the case of some derived distributions, most desirable changes — require
more invasive techniques. The final and most invasive type of
change — changes to code — is the most difficult but
also the most promising and powerful if it can be done sustainably.
Changes of this type involve bifurcations of the code-base and will
be the topic of the remainder of this paper.
Distributed Source Control
One promising method of maintaining deltas in forked or branched
projects lies in distributed version control systems (VCS).
Traditional VCS systems work in a highly centralized fashion. CVS,
the archetypal free software VCS and the basis for many others, is
based around the model of a single centralized server. Anyone who
wishes to commit to a project must commit to the centralized
repository. While CVS allows users to create branches, anyone with
commit rights has access to the entire repository. The tools for
branching and merging over time are not particularly good.
The branching model is primarily geared toward a system where
development is bifurcated and then the branch is merged completely
back into the main tree. Normal use of a branch might include
creating a development branch, making a series of development
releases while maintaining and fixing important bugs in the stable
primary branch, and then ultimately replacing the stable release
with the development release. The CVS model is not geared toward a system where an
arbitrary delta, or sets of deltas, are maintained over time.
Distributed version control aims to solve a number of problems
introduced by CVS and alluded to above by:
Allowing people to work disconnected from each other and to sync
with each other, in whole or in part, in an arbitrary and ad-hoc
fashion.
Allowing deltas to be maintained over time.
Ultimately, this requires tools that are better at merging
changes and in not merging
certain changes when that is the desired behavior. It also leads to
tools capable of history-sensitive merging.
The most famous switch to a distributed VCS model from a
centralized VCS model was the move by the Linux kernel development
community to the proprietary distributed version control system
BitKeeper. In his recent announcement of the decision to part ways
with BitKeeper, Linus Torvalds said:
In fact, one impact BK has had is to very fundamentally make us
(and me in particular) change how we do things. That ranges from
the fine-grained changeset tracking to just how I ended up trusting
sub-maintainers with much bigger things, and not having to work on
a patch-by-patch basis any more.[9]
At the time of the switch, free distributed version control
tools were less advanced than they are today. At the moment, an
incomplete list of free software VCS tools includes GNU Arch,
Bazaar, Bazaar-NG, Darcs, Monotone, SVK (based on Subversion), GIT
(a system developed by Linus Torvalds as a replacement for
BitKeeper) and others.
Each of these tools, at least after they reach a certain level
of maturity, allow or will allow users to develop software in a
distributed fashion and to, over time, compare their software and
pull changes from others significantly more easily than they could
otherwise. The idea of parallel development lies at the heart of
the model. The tools for merging and resolving conflicts over time,
and the ability to "cherry pick" certain patches or changes from a
parallel developer each make this type of development significantly
more useful than it has been in the past.
VCSs work entirely on the level of code. Due to the nature of
the types of changes that Ubuntu project is making to Debian's
code, Ubuntu has focused primarily on this model and Canonical
currently funds two major distributed control products — the
Bazaar and Bazaar-NG projects.
In many ways, employing distributed version control effectively
is a much easier problem to solve for small, more traditional, free
software development projects than it is for GNU/Linux
distributions. Because the problems associated with maintaining
parallel development of a single piece of software in a set of
related distributed repositories is the primary use case for
distributed version control systems, distributed VCS alone can be a
technical solution for certain types of parallel development. As
the tools and social processes for distributed VCS evolve, they
will become increasingly important tools in the way that free
software is developed.
Because the problems of scale associated with building an entire
derivative distribution are more complicated than those associated
with working with a single "upstream" project, distributed version
control is only now being actively deployed in the Ubuntu project.
In doing so, the project is focusing on integrating these into
problem specific tools built on top of distributed version
control.
Problem Specific Tools
Another technique that Canonical Ltd. is experimenting with is
the creation of high level tools built on top of distributed
version control tools specifically designed for maintaining
difference between packages. Because packages are usually
distributed as a source file with a collection of one or more
patches, this introduces the unique possibility of creating a
high-level VCS system based around this fact.
In the case of Ubuntu and Debian, the ideal tool creates one
branch per patch or feature and uses heuristics to analyze patch
files and create these branches intelligently. The package build
system section of the total patch can also be kept as a separate
branch. Canonical's tool, called the Hypothetical Changeset Tool
(HCT) (although no longer hypothetical), is one experimental way of
creating a very simple, very streamlined interface for dealing with
a particular type of source that is created and distributed in a
particular type of way with a particular type of change.
While HCT promises to be very useful for people making derived
distributions based on Debian, its application outside distribution
makers will, in all likelihood, be limited. That said, it provides
an example of the way that problem and context specific tools may
play an essential role in the maintenance of derived code more
generally.
Social Solutions
It has been said that it is a common folly of a technophile to
attempt to employ technical solutions toward solving social
problems. The problem of deriving software is both a technical
and social problem and
adequately addressing the larger problems requires approaches that
take into consideration both types of solution.
Scott James Remnant compares the relationship between
distributions and derived distributions as similar to the
relationship between distributions and upstream maintainers:
I don't think this is much different from how Debian maintainers
interact with their upstreams. As Debian maintainers we take and
package upstream software and then act as a gateway for bugs and
problems. Quite often we fix bugs ourselves and apply the patch to
the package and send it upstream. Sometimes the upstream don't
incorporate that patch and we have to make sure we don't
accidentally drop it each subsequent release, we much prefer it if
they take them, but we don't get angry if they don't.
This is how I see the relationship between Ubuntu and Debian,
we're no more a fork of Debian than a Debian package is a fork of
its upstream.
Scott alludes the fact that, at least in the world of
distributions, parallel development is already one way to view the
modus operandi of existing
GNU/Linux distributions. The relationship between a deriver and
derivee on the distribution level mirrors the relationship between
the distribution and the "upstream" authors of the packages that
make up the distribution. These relationships are rarely based
around technological tools but are entirely in the realm of social
solutions.
Ubuntu has pursued a number of different initiatives along these
lines. The first of these has been to regularly file bugs in the
Debian bug tracking system when bugs that exist in Debian are fixed
in Ubuntu. While this can be partially automated, the choice to
automate this and the manner in which it it is set up is a purely
social one.
However, as I alluded to above, Ubuntu is still left with
questions in regards to changes that are made to packages that do
not necessarily fix bugs or that fix bugs that do not exist in
Debian but may in the future. Some Debian developers want to hear
about the full extent of changes made to their software in Ubuntu
while others do not want to be bothered. Ubuntu should continue to
work with Debian to find ways to allow developers to stay in
sync.
There are also several initiatives by developers in Debian,
Ubuntu, and in other derivations to create a stronger relationship
between the Debian project and its ecosystem of derivers and
between Ubuntu and Debian in particular. While the form that this
will ultimately take is unclear, projects existing within an
ecosystem should explore the realm of appropriate social
relationships that will ensure that they can work together and be
informed of each others' work without resorting to "spamming" each
other with irrelevant or unnecessary information.
Another issue that has recently played an important role in the
Debian/Ubuntu relationship is the importance of both giving
adequate credit to the authors or upstream maintainers of software
without implying a closer relationship than is the case. Derivers
must walk a file line where they credit others' work on a project
without implying that the others work for, support, or are
connected to the derivers project to which, for any number of
reasons, the "upstream" author might not want to be associated.
In the case of Debian and Ubuntu, this has resulted in an
emphasis on keeping or importing changelog entries when changes are
imported and in noting the pedigree of changes more generally. It
has recently also been discussed in terms of the "maintainer" field
in each package in Ubuntu. Ubuntu wants to avoid making changes to
every unmodified source package (and introducing an unnecessary
delta) but does not want to give the impression that the maintainer
of the package is someone unassociated with Ubuntu. While no
solution has been decided at the time of writing, one idea involved
marking the maintainer of the package explicitly as a Debian
maintainer at the time that the binary packages are built on the
Ubuntu build machines.
The emphasis on social solutions is also essential when using
distributed VCS technology. As Linus Torvalds alluded to in the
quote above, the importance of technological changes to distributed
VCS technology is only felt when people begin to work in a
different way — when they begin to employ different social
models of developer interaction.
While Ubuntu's experience can provide a good model for tackling
some of these source control issues, it can only serve as a model
and not as a fixed answer. Social solutions must be appropriate for
a given social relationship. Even in situations where a package is
branched because of social disagreements, a certain level of
collaboration on a social level will be essential to the long term
viability of the derivative.
Conclusions
As the techniques described in this paper evolve, the role that
they play in free software development becomes increasingly
prominent and increasingly important. Joining them will be other
techniques and models that I have not described and cannot predict.
Because of the size and usefulness of their code and the size of
their development communities, large projects like Debian and
Ubuntu have been forced into confronting and attempting to mediate
the problems inherent in forking and deriving. However, as these
problems are negotiated and tools and processes are advanced toward
solutions, free software projects of all sizes will be able to
offer users exactly what they want with minimal redundancy and
little duplication of work. In doing this, free software will
harness a power that proprietary models cannot compete with. They
will increase their capacity to produce better products and better
processes. Ultimately, it will help free software capture more
users, bring in more developers, and produce more free software of
a higher quality.
[3] I spearheaded and help build a now mostly
defunct derivation of Debian called Debian-Nonprofit (Debian-NP)
geared for non-profit organizations by working within the Debian
project.