There is no good, free, version control system for documents or documentation. The creation of any piece of literature, especially one that involves multiple authors working on the document concurrently, involves adding, removing, and changing text constantly. There is no good way to keep track of these changes in the way that there is for source code. Existing solutions are proprietary and/or kludgey.
conflict--they have both rewritten or edited the same paragraph, sentence, or word. Perhaps this alone is not a problem but there is no good way to resolve these conflicts. This acts to discourage collaborative creation--at least in an asynchronous fashion (
Edit this document and I'll wait until you send it back to me);
brancha document in the way that programmers can with source code. A branch may involve an author who wants to do major work or reorganization on a document may want to it do it separately while letting work on the document (spelling and grammar fixes, minor additions, continue). Then he/she would merge the two branches back together when the major changes were ready.
Current solutions
seem to fall into a couple major
categories. Each has his own benefits and shortcomings. Some of
these include:
Source-level VCSs: The technique I currently use involves putting my documents into a VCS intended for source code like RCS, CVS or subversion (SVN) one of many proprietary alternatives with similar functionality.
CVS will track changes and allow multiple authors to work on a document simultaneously--just as it does with source code. However, there are at least two major drawbacks:
Microsoft Word's Track Changes Function: This method provides perhaps the most successful solution I've seen so far. However, because Word is proprietary software, it is unacceptable for my purposes. On the other hand, OpenOffice.Org (a free alternative to Word) provides similar types of functionality in a free package.
Track Changes acts as the name implies: using the function, Word or OpenOffice will log changes made to a document. When the document is sent to a friend, the word processer can display the changes in an intelligent, interactive interface that will let the author check the changes one by and one and approve, deny, or edit them.
I've seen offices and organizations make heavy use this feature, in conjunction with a SMB (windows file-sharing) network share folder to work on documents as group. However, this collaboration must be tightly controlled and well organized as there as this solution introduces several major drawbacks.
checked outat any one point.
I propose a robust, free version control system specifically
designed for working with documents--especially in a
asynchronous collaborative environment. I'll refer to this
(non-existent) system as CODEX, or the Collaborative Online
Documentation (D)ifference Extractor. The software will be free
software
and will be distributed under the terms of the
GNU GPL. The core engine will be written in either Perl or
Python.
Since my software will be free software, I will seek to not duplicate effort where-ever possible. I think that building off a system like CVS or subversion will be the logical first step. Since a diff will show every changed line, it will by default show every changed word and piece of white space. A contextual diff (which both CVS and subversion can provide) will include even more information. Either of these programs will be able to provide information useful for resolving conflicts and will provide the ability to commit, checkout, release or watch a project. They also both provide servers with several methods to use interface over a LAN or the Internet. A future version of subversion will allow for different client-side diff programs.
I do NOT want this project to involve creating a new word processor. There are more than enough of them, most of them bad. I would almost certainly create another bad one. I want my software to be able to work with many other word processors so that it might be picked up an incorporated as a back-end to existing pieces of software.
Taking this method, my software will act as interface between the user (or their word processing software) and the VCS.
Along the lines I'm considering right now, the software might:
commit,
checkout, and
updateto/from the VCS system, running on the local machine or a server on a LAN or the Internet;
To accomplish this, my software will actually need to be two distinct pieces.
plug-insfor:
In this way, what I aim to create in this project will be more of a framework for creation, transmission, and handling of this type of data. I will aim to define this framework and get example code written as a proof of concept. Hopefully, with this out there, other developers will be able to contribute and expand the scope, and usability of the software.
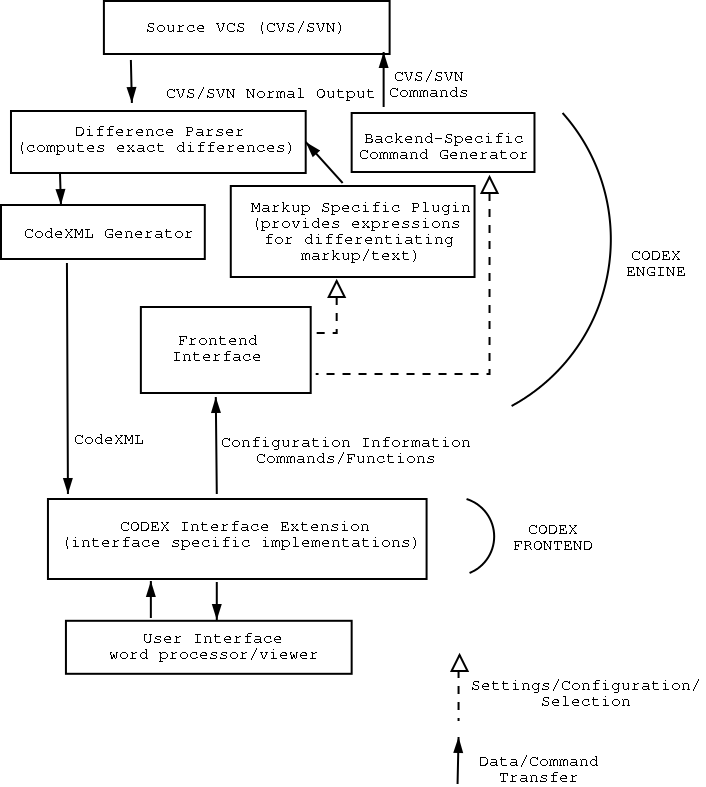
This diagram shows how some of the internals of the CODEX engine might work.
In creating my proof of concept this year, I'll aim to create (in this order):
This is what I have so far and a lot it is right off the top of my head. This is a RFC. Please email me back at mako@debian.org.